
导读:“We分析”是微信小程序官方推出的数据分析平台,其中画像洞察是其中一个非常重要的功能模块。微信开发工程师钟文波将描述We分析画像系统各模块是如何设计,在介绍基础标签模块之后,重点讲解用户分群模块设计。希望相关的技术实现思路,能够对你有所启发。
 背景介绍
背景介绍
1)画像系统简述
“We分析”是小程序官方推出的数据分析平台,其中画像洞察是其中一个重要的功能模块。该功能将为用户提供基础的画像标签分析能力,同时提供自定义的用户分群功能,以满足更多个性化的分析需求及支撑更多的画像应用场景。在此之前,原有MP的画像分析仅有基础画像,相当于只能分析小程序大盘固定周期的基础属性,而无法针对特定人群或自定义人群进行分析及应用。我们头部商户均希望平台提供完善的画像分析能力。除最基础的画像属性之外,支持更丰富的标签及更灵活的用户分群应用能力。因此,“We分析”在相关能力上计划进行优化。2)画像系统设计目标
易用性:易用性主要指商户在使用画像洞察功能的时候,不需要学习成本就能直接上手使用,结合自身业务场景解决问题,做到开箱即用,对商户0门槛。稳定性:稳定性指系统稳定可靠体验好,例如画像标签数据、人群包按时稳定产出,在交互使用过程中查询速度快,做到如丝般顺滑的手感。完备性:指数据丰富、规则灵活、功能完善;支持丰富的人群圈选数据,预置标签+人群标签+平台行为+自定义上报行为等,做到用户想要的数据,在不违反隐私的情况下平台基本提供。支持灵活的标签及人群创建方式,用户按照自己的想法任意圈选出想要的人群,按不同周期手动或自动选出人群包。支持人群的跟踪分析,人群在多场景的应用等。画像系统整体概述
系统从产品形态的角度出发,分成2个模块进行描述,分别是基础标签模块及用户分群模块。系统的数据流向图如下:数据源包括用户属性、人群标签、平台行为数据、自定义上报数据;其中,用户属性指用户自身或者用户设备的特征,如用户的性别、地域、品牌机型等信息;人群标签指用户活跃、流失等类型的标签;平台行为是官方上报的数据,如访问、分享等数据;自定义上报数据,指商户通过We分析的上报链路,将商户自己想分析的行为上报上来的数据。
主要是对用户属性、人群标签、平台行为进行相应的ETL及预计算。根据用户定义的用户分群规则,从多源数据中计算出对应的人群。画像及人群数据在tdw加工好后,从tdw分布式hdfs集群导入到线上的tdsql、clickhouse存储;其中,预计算的数据导入到线上tdsql存储,用户行为等明细数据导入到线上clickhouse集群中。提供在线的画像服务接口,其中标签管理使用通用配置系统,数据服务rpc框架用的是svrkit-javamesh,在上一层是我们的数据中间件,统一做了流量控制、异步调用、调用监控、及参数安全校验。提供基础标签分析及针对特定人群的标签分析,及人群圈选跟踪分析及线上应用等。 基础标签模块
基础标签模块
1)功能描述
该模块主要为满足商户对画像的基础性需求,预期希望能满足绝大部分中长尾商户对画像的使用深度要求。主要提供的是针对小程序大盘的基础标签分析,及针对特定人群(活跃:1天活跃、7天活跃、30天活跃、180天活跃,交易:1天交易、7天交易、30天交易)的特定标签分析。如下所示:2)技术实现
通过对上述功能的描述,可以看出功能的特点是官方定义数据范围可控,支持的是针对特定人群的特定标签分析。针对特定人群的特定标签分析数据是用离线T+1的hive任务进行计算,流程如下,分别计算官方特定标签的统计数据,特定人群的统计数据,以及计算特定人群交叉特定标签的数据。不同存储对比存在差异。通过上述分析,我们这里需要存储的是预计算好的结果数据,同时业务的特点是按照小程序appid粒度进行多个数据主题统计的存储,第一直觉是适合用分布式OLTP存储;同时也对比了不同的数据库,在选型过程中,主要考虑的点包括:数据的写入,读取性能进行对比。
写入包括是否可以支持快速的建表等DDL操作,平台数据指标多,例如We分析平台数据,指标近千个。不同的场景主题指标一般会分别进行计算,写入到不同的在线存储数据表中,所以需要具备快速DDL及高效出库数据的能力。读取包括查询性能,读取接口是否简单灵活,开发是否简单;以及相关运维配套设施是否完善,如监控告警、扩容、权限、辅助优化等。TDSQL有优势。通过对上述存储引擎的对比,We分析平台基本所有的预计算结果数据,最终选用TDSQL来存储离线预计算结果数据,关于TDSql的几个关键点如下:
第一,存储容量:TDSQL当前支持最大64个分片,每个分片最大3T,单个实例最大能支持存储192T的数据。第二,数据出库:通过数平US上的出库组件可以完成数据从tdw直接出库到TDSQL,近1亿数据量可以在40min+完成出库,出库组件的监控及日志完善。第三,查询性能:2个分片,8核32G进行测试,查询某小程序一段时间数据,查询QPS 5W。第四,读取方式:通过jdbc连接查询,拼接不同sql进行查询,查询方式简单灵活。第五,运维方面:实例申请、账号设置、监控告警、扩容、慢查询分析等都可以开发自助在云控制台完成。第六,开发效率:DDL操作简单,数据开发从建表到出库基本没有学习成本,问题定位简单高效。当前整个平台的预计算数据出库到TDSQL的数据达10亿/天,数据表200+张,实际使用存储100T+。TDSQL整体功能较为全面,开发者仅需要补充开发数据生命周期管理工具,删除方式的注意点跟msyql一样。如果采用KV类型的引擎进行存储,需要根据KV的特性合理设计存储Key,同时在查询端,对key进行拼接组装,发送BatchGet请求进行查询,整个过程开发逻辑会相对多些,需要更加注重Key的设计。例如,实现一个只有概要数据的趋势图,那么我们存储的Key需要设计成类似格式:{日期}#{小程序appid}#{指标类型}。 用户分群模块
用户分群模块
1)功能描述
该模块主要提供自定义的用户分群能力,用户分群是依据用户的属性及行为特征将用户群体进行分类,以便对其进行观察分析及应用。自定义的用户分群能够满足中头部商户的个性化分析运营需求,例如,商户想看看上次618参加了某活动的用户人群,在接下来的活跃交易趋势跟大盘的差异对比;或者商户想验证对比某些人群对优惠券的敏感程度,圈选人群后通过AB实验进行验证,类似的应用会非常多。在功能设计上,我们需要做到数据丰富、规则灵活、查询快速,支持丰富的人群圈选数据,预置标签+人群标签+平台行为+自定义上报行为等,做到用户想要的数据,在不违反隐私的情况下平台基本提供;支持灵活的标签及人群创建方式,用户按照自己的想法任意圈选出想要的人群,按不同周期手动或自动选出人群包,支持人群的跟踪分析,人群在多场景的应用能力。2)人群包实时预估
人群包实时预估是根据用户定义的规则,计算出当前规则下有多少用户命中了该规则,产品交互通常如下所示。为了满足商户随意根据自己的想法圈出想要的人群,我们支持丰富的数据源,包括预置标签+人群标签+平台行为数据+自定义上报数据。整体画像的数据量较大,其中预置的标签画像在离线hdfs上的竖表存储达5000亿/天,平台行为200亿+/天,且维度细,自定义上报行为50亿/天。怎么设计能节省存储同时加速查询是重点考虑的问题之一,大体的思路是会对预置标签画像转成bitmap进行压缩存储,对平台行为明细进行预聚合及对维度枚举值进行ID自增编码,字符串转成数据整型节省存储空间,同时在产品层面增加启用按钮,开通后导入近期数据,从而控制存储消耗,具体细节如下。属性标签数据:通常建设用户画像的核心工作就是给用户打标签,标签是人为规定的高度精炼的特征标识,如性别、年龄、地域、兴趣,也可以是用户的一些行为集合。这些标签集合抽象出一个用户的信息全貌,每个标签分别描述该用户的一个维度,各标签维度间相互联系,构成对用户的整体描述。当前的用户属性及人群标签是由平台方提供,由平台每天进行统一的加工处理生成官方标签,平台暂时没有支持用户自定义的标签,因此这里主要说明平台标签是如何计算加工管理。
例如活跃标签 10002,对标签的每个标签值进行编码如下:对特定人群进行编码,基准人群是作为必选的过滤条件,用于限定用户的范围:第二,标签离线存储。标签数据在离线的存储上,采用竖表的存储方式。表结构如下所示,标签之间可以并行构建相互独立不影响。采用竖表的结构设计,好处是不需要开发画像大宽表,即使任务出现异常延时也不会影响到其它标签的产出,而画像大宽表需要等待所有画像标签均完成后才能开始执行该宽表数据的生成,会导致数据的延时风险增大,也会出现说当需要新增或删除标签时,需要修改表结构。因此在线的存储引擎是否支持与离线竖表模式相匹配的存储结构成为我们很重要的考量点。采用大宽表方式的存储,比如Elasticsearch和公司的Hermes存储,需要等待全部需要线上用到的画像标签在离线计算环节加工完成才能开始入库。而像Clickhouse、Doris则可以采用与竖表相对应的表结构,标签加工完成就可以马上出库到线上集群,从而减小因为一个标签的延时而导致整体延时的风险。CREATE TABLE table_xxx( ds BIGINT COMMENT '数据日期', label_name STRING COMMENT '标签名称', label_id BIGINT COMMENT '标签id', appid STRING COMMENT '小程序appid', useruin BIGINT COMMENT 'useruin', tag_name STRING COMMENT 'tag名称', tag_id BIGINT COMMENT 'tag id', tag_value BIGINT COMMENT 'tag权重值')PARTITION BY LIST( ds )SUBPARTITION BY LIST( label_name )( SUBPARTITION sp_xxx VALUES IN ( 'xxx' ), SUBPARTITION sp_xxxx VALUES IN ( 'xxxx' ))
第三,标签在线存储。我们把标签理解成对用户的分群,那么符合某个标签的某个取值的所有用户ID(UInt类型)就构成了一个个的人群,bitmap是用于存储标签-用户的映射关系的非常理想的数据结构,最终我们需要的是构建出每个标签的每个取值所对应的bitmap;例如,性别这个标签组,背后对应的是男性用户群和女性用户群。性别标签:男 -> 男性用户人群包,女 →女性用户人群包。平台行为数据:平台行为指官方进行上报的行为数据,例如访问、分享、交易等行为数据,商户不需要进行任何埋点等操作。我们主要是会对平台行为进行预聚合,计算同一维度下的PV数据,已减少后续数据的存储及计算量。
同时会对维度枚举值进行ID自增编码,目的是减少存储占用,写入以及读取性能;从效果来看我们对可枚举类型进行字典ID编码对比原本字符类型能节省60%的线上存储空间,同时相同数据量条件下带来2倍查询速度提升。自定义上报数据:自定义上报数据是商户自己埋点进行数据的上报,上报的内容包括公共参数及自定义内容,其中自定义内容是key-value的格式,在OLAP引擎中我们会将用户自定义的内容转成map结构类型进行存储。
首先讲下,在线OLAP存储选型。标签及行为明细数据的存储引擎选型对于画像系统至关重要,不同的存储引擎决定了系统不同的设计方式;我们调研了解到,我们公司内外在建设画像系统上,有多种不通过的存储方案。我们对常用的画像OLAP引擎做了对比,如下:
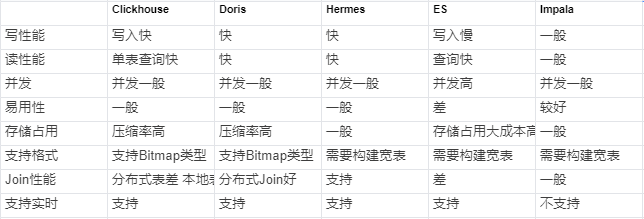
综合上述调研,我们采用Clickhouse作为画像数据存储引擎。在Clickhouse中使用RoaringBitmap作为Bitmap的解决方案,该方案支持丰富的bitmap操作函数,可以十分灵活方便的判重和进行基数统计操作,如下所示。采用RoaringBitmap(RBM)对稀疏位图进行压缩,可以减少内存占用并提高效率。该方案的核心思路是,将将32位无符号整数按照高16位分桶,即最多可能有216=65536个桶,称为container。存储数据时,按照数据的高16位找到container(找不到就会新建一个),再将低16位放入container中,也就是说,一个RBM就是很多container的集合,具体参考高效压缩位图RoaringBitmap的原理与应用。数据导入线上存储:在确定了采用什么存储引擎存储线上数据后,我们需要将离线集群的数据导入到线上存储,其中对于标签数据通常的做法是将原始明细的id数据直接导入到ClickHouse表中,再通过创建物化视图的方式构建RBM结构进行使用。问题是我们的明细数据非常大每天有5000亿+,这样的导入方式给Clickhouse集群带来了很大资源开销。而通常我们处理大规模数据都是用Spark这样的离线计算框架来完成处理。最后我们也是把预处理工作全部交给了Spark框架,这种方式大大的减少了写入的数据量,同时也减少了Clickhosue集群的处理压力。
具体步骤是Spark任务首先会按照useruin进行分片处理,然后对每个分片中标签的每个标签值生成一个Bitmap,保证定制的序列化方式与ClickHouse中的RBM兼容。其中通过Spark处理后的bitmap转成string类型,然后写入到线上的标签表中,在表中我们定义了一个物化列字段,用于实际存储bitmap,在写入过程中会将序列化后的bitmap字符串通过base64Decode函数转成Clickhouse中的AggregateFunction(groupBitmap, UInt32)数据结构,具体表结构如下:CREATE TABLE wxg_mmbiz_dw.xxx_table_local on CLUSTER xxx( `ds` UInt32, `appid` String, `label_group_id` UInt64, `label_id` UInt64, `bucket_num` UInt32, `base64rbm` String, `rbm` AggregateFunction(groupBitmap, UInt32) MATERIALIZED base64Decode(base64rbm))ENGINE = ReplicatedMergeTree('/clickhouse/tables/{layer}-{shard}/xxx_table_local', '{replica}')PARTITION BY toYYYYMMDD(toDateTime(ds))ORDER BY (appid, label_group_id, label_id)TTL toDate(ds) + toIntervalDay(5)SETTINGS index_granularity = 16
具体实现参考:SparkSQL & ClickHouse RoaringBitmap使用实践 ,我们主要是在此基础上,增加了分桶写入的功能。存储占用问题:标签类型数据用bitmap类型存储后,在集群一个分片占用的存储850G,8分片*双副本总计占用存储14T;平台行为当前累计40亿,集群单分片占用存储32G,8分片*双副本总计占用存储512G,预计随着商户的使用的增多,预估数据增长20倍左右占用10T存储。
数据查询方式:人群圈选过程中,如何保障大的APP查询,在复杂规则情况下的查询速度,我们在导入过程中对预置画像+平台行为+自定义上报行为均按相同分桶规则导入集群,保证一个用户仅会在同一台机器,查询时始终进行本地表查询,避免进行分布式表查询。
对于查询性能的保障,我们始终保证所有查询均在本地表完成,上面已经介绍到数据在入库时,均会按照相同用户ID的hash分桶规则出库到相应的机器节点中。另外使用维度数字编码,测试数字编码后对比字符方式查询性能有2倍以上提升。对标签对应的人群转成Bitmap方式处理,用户的不同规则到最后都会转成针对bitmap的交并差补集操作。对于平台行为,如果在用户用模糊匹配的情况下,会先查询维度ID映射表,将用户可见维度 转化成维度编码ID,后通过编码ID 及规则构建查询SQL。整个查询的核心逻辑是根据圈选规则组合不同查询语句,然后将不同子查询通过规则组合器最终判断该用户是否命中人群规则。基于Svrkit-javamesh开发服务接口:Svrkit-javamesh是我们团队开源的高性能RPC框架,目前已有多个部门在使用,可以理解成类似trpc-java的框架,是用java来开发rpc服务。
在数据服务的上一层是我们的数据中间件,统一做了流量控制、异步调用、调用监控、及参数安全校验,特别是针对用户量较大的APP在多规则查询时,耗时较大,因此我们配置了细粒度的流量控制,保障查询请求的有序及服务的稳定可用。查询性能数据:第一,不同DAU等级小程序查询性能。
从性能数据看,对于用户量大的app,在规则非常多的情况下还是要大几十秒,等这么长时间体验还是没那么的好。因此对于这部分用户量大的app我们采用的策略是抽样,通过抽样速度能得到非常大的提升,并且预估的准确率误差不大,在可接受的范围内;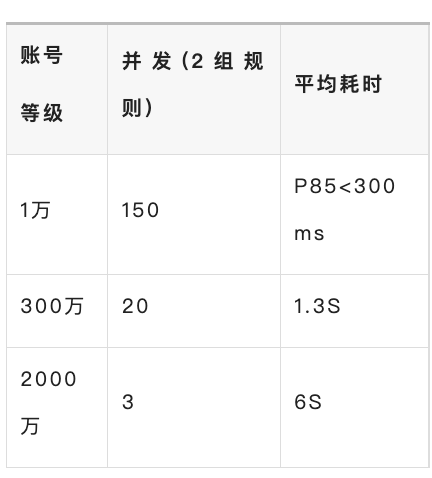
3)人群创建
人群包实时创建类似上面描述的人群大小实时预估,区别是在最后人群创建是需要将圈选的人群包用户明细写入到存储中,然后返回人群包的大小给到商户。同样是在本地表执行,生成的人群包写入到同一台机器中,保持分桶规则的一致。用户创建的例行化人群包,需要每天计算,如何持续跟踪分析趋势,并且不会对集群造成过大的计算压力?我们的做法利用离线超大规模计算的能力,在凌晨启动所有人群计算任务,从而减小对线上Clickhouse集群的计算压力。所有小程序商户创建的例行化人群包计算集中到凌晨的一个任务中进行,做到读一次数据,计算完成所有人群包,最大限度节省计算资源,详细的设计如下:首先,我们会先将全量的数据(标签属性数据+行为数据)按照小程序appid粒度及选择的时间范围进行过滤,保留有效的数据;其次,对数据进行预聚合处理,将用户在一段时间范围的行为数据,标签属性镜像数据按照小程序的用户粒度进行聚合处理,最终的数据将会是对于每个小程序的一个用户仅会有一行数据;那么人群包计算,实际上就是看这个用户在某个时间范围内所产生的行为及其标签属性特征是否满足商户定义的人群包规则;最后,对数据按用户粒度聚合后进行复杂的规则匹配,核心是拿到一个用户某段时间的行为及人群标签属性,判断这个用户满足了商户定义的哪几个人群包规则,满足则属于该人群包的用户。4)人群跟踪应用
在按照用户规则圈选出人群后,统一对人群进行常用指标(如活跃、交易等指标)的跟踪。整个过程用离线任务进行处理,会从在线存储中导出实时生成的人群包,以及离线批量生成的定时人群包,汇总一起,后关联对应指标表,输出到线上OLTP存储进行在线的查询分析。其中,导出在线人群包会在凌晨空闲时间进行,通过将人群RBM转成用户明细ID,具体方法为:arrayJoin(bitmapToArray(groupBitmapMergeState(rbm)))。人群基础分析对一个自定义的用户分群进行基础标签的分析,如该人群的省份、城市、交易等标签分布。人群行为分析,分析该人群不同的事件行为等。在AB实验中的人群实验,商户通过规则圈选出指定人群作为实验组(如想验证某地区的符合某条件的人群是否更喜欢参与该活动),跟对照组做相应指标的对比,以便验证假设。
