{kind=link}
从0到10亿,微信后台架构及基础设施设计与实践!
摘要:微信后台业务类型众多,包括即时通信,社交网络,金融支付等等。本次分享着重讨论如何在海量用户场景下,后台架构设计中的共性部分如高可用、强一致、快速迭代等等,微信是如何在不断变化的背景下设计统一的架构与基础设施来解决核心难题。

许家滔,微信技术架构部后台总监,专家工程师,多年来伴随QQ邮箱和微信后台成长,历经系统从0到10亿级用户的过程。目前负责微信后台工作,包括消息,资料与关系链,后台基础设施等内容。
本文根据许家滔老师在2018年10月17日【第十届中国系统架构师大会(SACC2018)】现场演讲内容整理而成。
01
回顾微信发展历程

2011年,我们发布了第一版微信,2012年,推出视频聊天功能。如今,微信的活跃用户数已经达到10亿。后台涉及到的技术很多,我这边主要聚焦于数据存储、微服务等。
02
微信后台系统架构

这是最新的微信后台系统架构图,逻辑上最前面会有一个终端,后面会有一个长链接接入层,在线有几亿的管理连接部分。底层上,因为数据比较敏感而且数据量比较大,所以我们的存储并没有基于开源来搭建,而是自己开发了一整套存储,这也是迭代比较多的部分。
最开始,也就是2011年,我们用的是第一代存储。早期的微信与QQ不同,它更像是一个邮箱。
这几年,我们逐渐完善,包括内部安全、管理等。
目前,我们最关心的有两个方面,一是高可用。微信作为一个国民应用,对高可用有着极高的要求,是不可以停顿的。早期的微信迭代速度很快,几乎每两周一个版本,还包括大量的修改。二是敏捷开发的一些问题。例如内存泄露、Coredump等。
03
数据业务背景与挑战
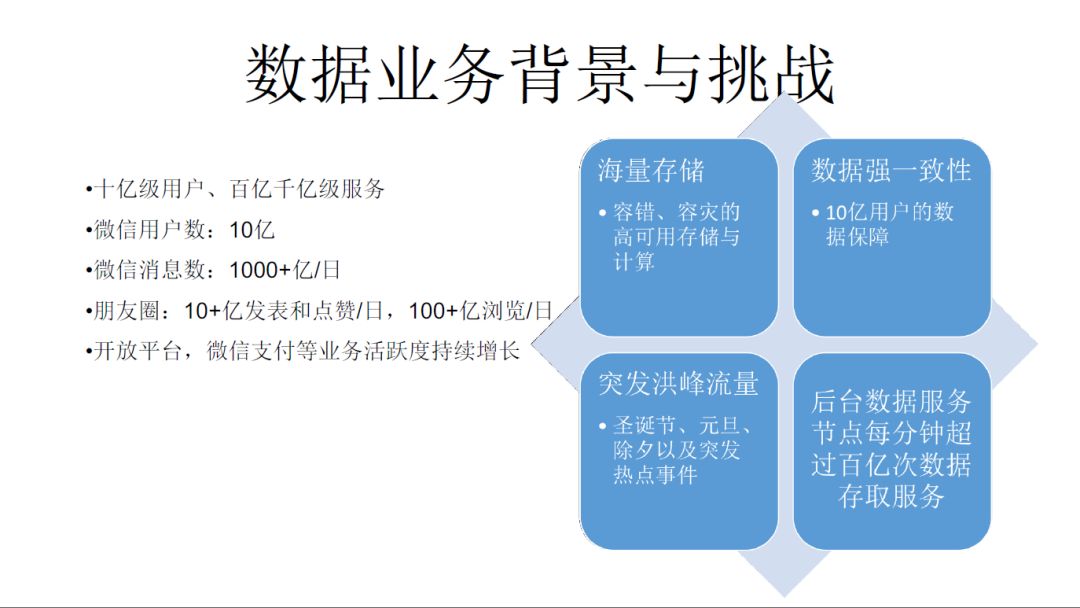
接下来,我重点讲一下数据存储和微服务框架这两块。今天的微信,用户数达10亿,每天的微信消息达1000+亿,朋友圈每日发表和点赞数达10+亿,每日浏览数达100+亿,开放平台,微信支付等业务活跃度持续增长。
总结成如下四大挑战:
1.海量存储
我们需要一个能容错、容灾的高可用存储与计算的框架;
2.数据强一致性
保障10亿用户数据不会出现问题;
3.突发洪峰流量
圣诞节、元旦、除夕以及突发热点事件;
4.后台数据服务节点每分钟超过百亿次数据存取服务;
04
目标
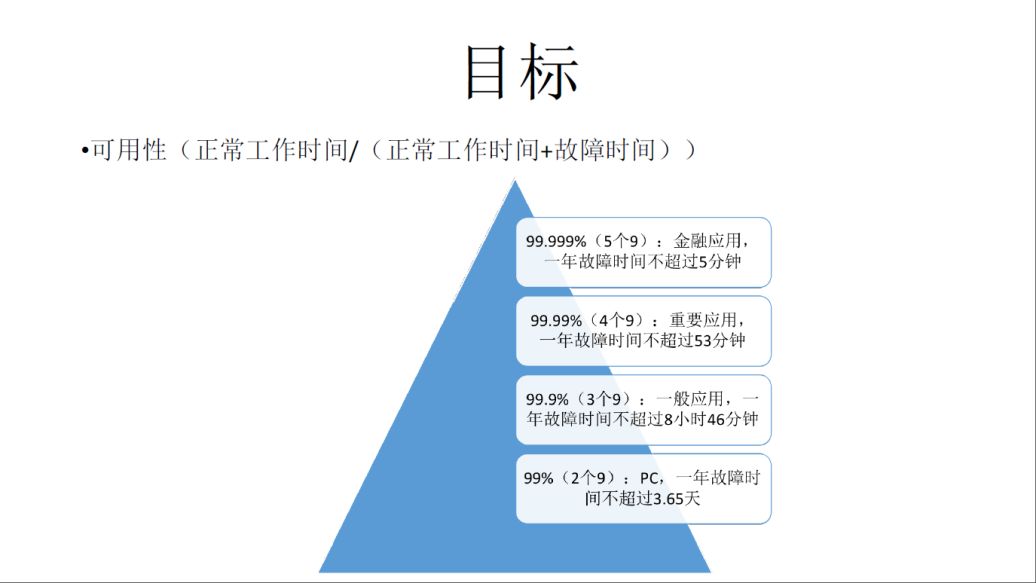
关于可用性,大家可能已经很熟悉了,这里我再细化一下。
最下面的2个9,是指一年故障时间不超过3.65天;最上面5个9 ,是指金融应用,一年故障时间不超过5分钟。
那么微信是一个什么样的应用呢?微信包含了金融应用,也就是大家常用的微信支付。
那么我们希望达到怎样的目标呢?有两大点:
1、机器故障是常态,微信希望提供连续无间断的服务能力
业界数据可用性通常通过RAFT,Paxos租约等来实现数据复制
机器故障时,系统会进入等待租约过期并重新选主的状态,即会产生30秒级别的服务中断,我们希望能够规避。
2、相对于传统的基于故障转移的系统设计,我们需要构建一个多主同时服务的系统
系统始终在多个数据中心中运行
数据中心之间自适应地移动负载
透明地处理不同规模的中断(主机,机房,城市园区等)
05
关键设计
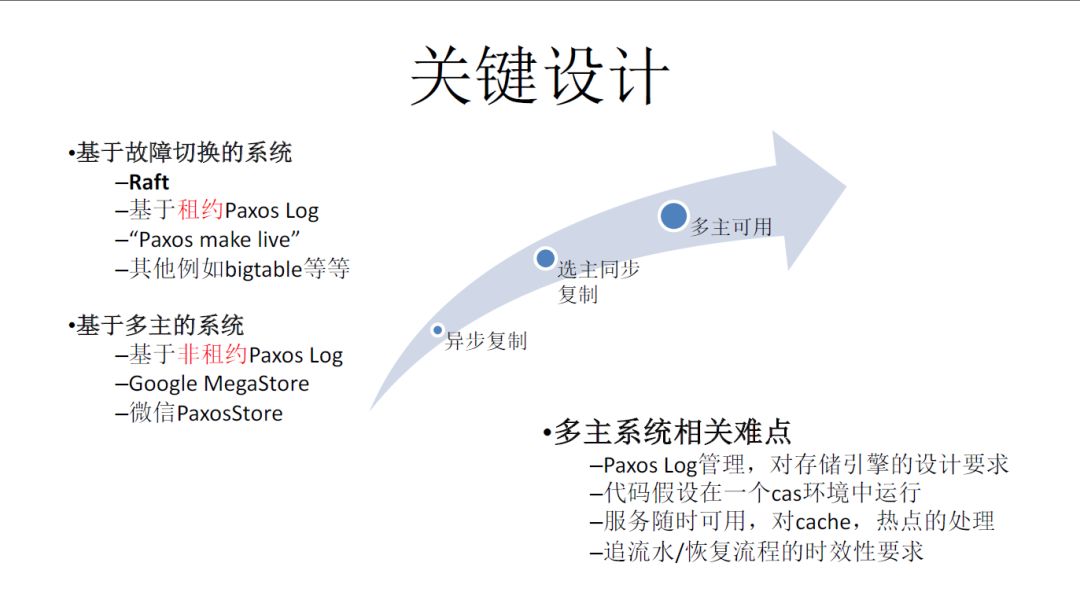
微信关键技术演变。最初,微信是异步复制,比较传统的一个场景。中间这部分是选主同步复制。
业界有两种比较经典的系统:一种是基于故障切换的系统,包括两个主要的协议,Raft协议和基于租约Paxos Log。来保证数据的一致性,但对服务的可用性有一定影响。另一种是基于多主的系统,是在可用性方面做的最彻底的系统。它是基于非租约Paxos Log,Google MegaStore以及微信PaxosStore。
多主系统有很多的难点。第一, 海量Paxos Log管理,对存储引擎的要求很高;第二,代码假设在一个cas环境中运行。
要做到服务随时可用,对cache和热点处理的要求很高。同时它对于追流水/恢复流程有时效性的要求。
06
多主系统的收益
多主系统收益很大,可以分为几个点。
一是7×24小时的可用性,它可以应对有计划和无计划的停机维护。不再有封尘已久的切换流程,由于多主可用,类似快照与数据对齐等行为,已经在在线核心逻辑中充分体现。其次是变更发布,因为这些系统写出来并非一直不变,最大的可用性需求是来自于我们的程序版本发布。
第二点是资源调度,当系统变多主之后,相当于有了多台随时都可以用的机器,它们的模式都是一样的,为了回避弱的节点去使用更多计算资源,只要切流量就可以了。所以切存储跟切逻辑是一样的,统称为切流量。
最后一点是成本,多主系统的预留冗余成本是相对低的,因为所有的机器都可以服务用户,所以在多主系统方面我们只需预留1/3的成本即可。
07
设计与实践
微信的设计主要分为三大块:
第一,实现同步复制,在数据分区内部实现完整ACID语义,维护细粒度的海量数据分区,且每一次数据读写都基于非租约的Paxos交互实现,每分钟超过百亿次。
第二,存储引擎方面,针对微信丰富的业务场景,设计多种高性能的存储模型,其次,我们还支持单表过亿行的二维表格/FIFO队列/key-value等数据结构。
第三,负载均衡方面,我们希望存储系统可以动态切换计算资源,数据节点动态计算负载能力尽力服务,超过服务能力部分自动转移到其他复制节点。
08
实际成果

目前微信的实际成果,核心数据存储服务可用性达6个9。整个系统有一个创新的技术点,具体细节我们发表在:
http://www.vldb.org/pvldb/vol10/p1730-lin.pdf
论文相关示例代码开源:github.com/tencent/paxosstore。
早期大家对Paxos算法都是认为很难实现的,近两年逐渐有一些公司开始对这方面有一些分享。上面提到的这个论文是微信PaxosStore的一点创新,贡献出了一些简洁的算法实现流程,大家可以很轻松的去理解和实现。
09
PaxosStore广泛支持微信在线应用
这些数据的应用基本都是PaxosStore在支持。
10
PaxosStore整体架构
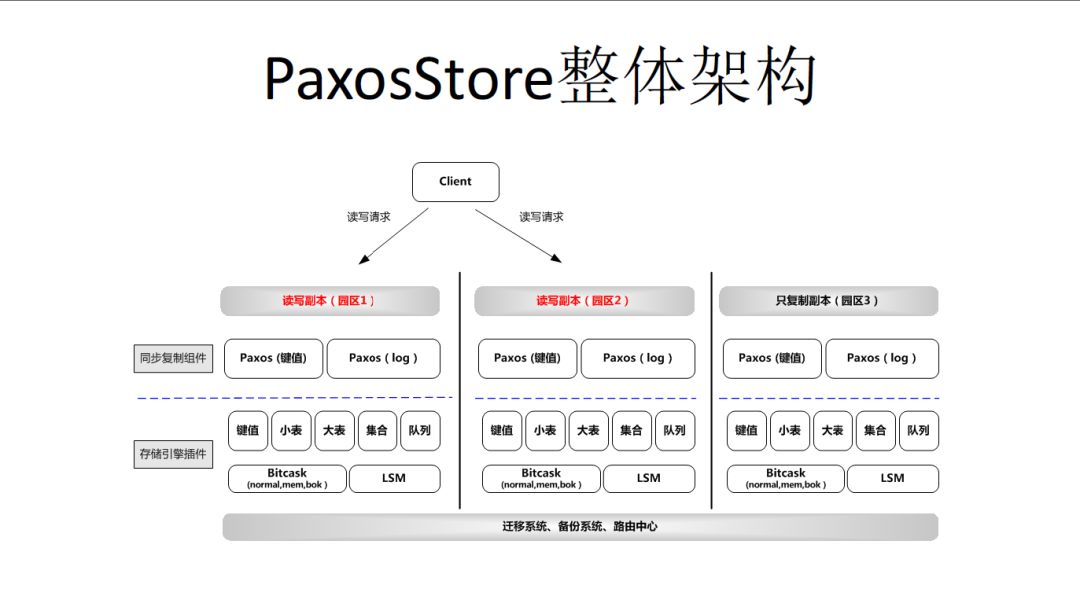
下面,简单介绍下PaxosStore的整体架构。
分成几个园区,园区必须有独立的网络和电力。 举个例子,假设有些机房实际上共享了一套电力甚至交换机的话,只要单点故障一样会挂掉。
所以,园区只是一个概念,至少要满足网络和电力独立,然后在考虑跨层或跨省的问题,PaxosStore实际上也有跨华东,华南,华北三个遥远距离的服务。
中间我们会把PaxosStore共识层和计算层、存储层分离起来,PaxosStore其实是一整套框架,它可以容纳不同的共识算法和存储。
下面是一个存储引擎。微信的存储引擎包括很多种,最早是Bitcask模型,现在广泛使用的是LSM,它可以支持比较多的业务。
最下面是迁移系统、备份系统、路由中心。
PaxosStore支持类SQL的filter,format,limit,groupby等能力,单表可以支持亿行记录。下一步,我们可能会根据业务的需求去开展。
11
PaxosStore:数据分布与复制
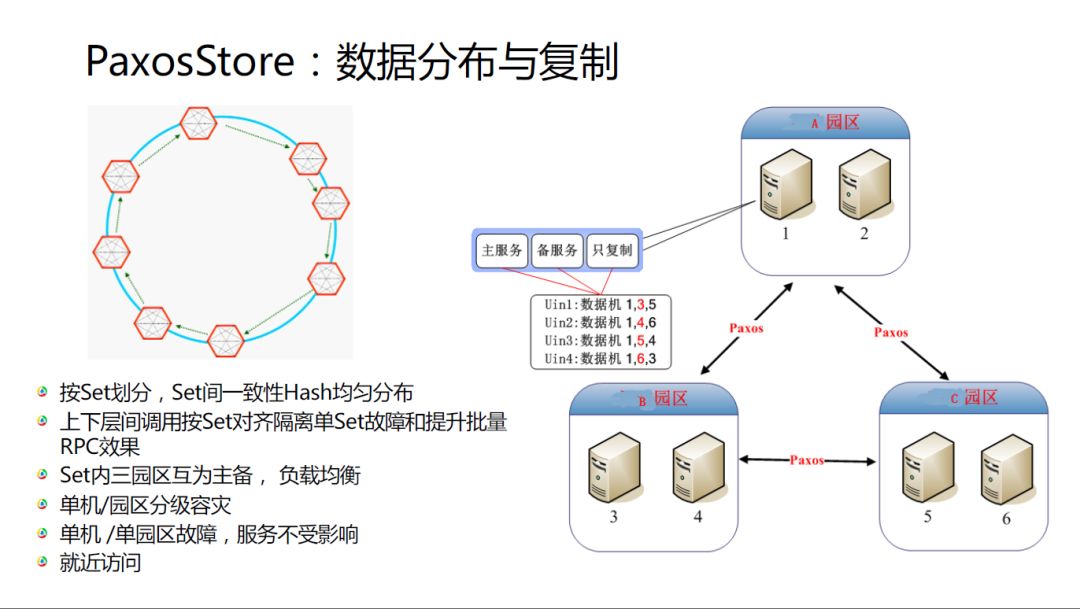
这一套分布式,其实是延伸了之前老系统的分布方式,数据会分成两层,它会按一致性hash划分到不同的节点。每个节点都有六个节点,它们交叉实现了复制的逻辑,可以达到一个比较好的负载均衡。
12
基于PaxosStore的在线基础组件
2017年之后,将整个微信90%的存储切完后,继续往下发展。随着业务的发展,我们把很多的立体图连起来。有了PaxosStore框架之后,很多系统都相对容易实现,像比较典型的zookeeper、hdfs、hbase等。
除了基本的数据系统之外,我们还有很多特殊的场景,例如远距离跨省常量存储。如,微信支付订单等场景,都有强烈的数据库需求,而且需要跨省容灾。
什么是远距离?考虑到故障的实际影响范围以及专线的物理情况,在地点的选择上,是有一定要求的,因此,在选点的选择上,一般选在整个中国跨越比较远的一些地方,如,上海、深圳、天津,构成了一个三角,相互间距大概2000公里左右。但有个实际问题,如果跨省,必须给它大概三四十毫秒左右的延迟。另外,像深圳跟汕头,上海跟天津,这些都不算远距离跨省。如果上海挂了,杭州的线也一定会出现问题,因为它俩距离比较近。
常量存储有什么特点?它的写需要有跨越三四十毫秒的跨城通信过程,但读是本地的。
另外,我们还针对微信支付复杂业务定制了事务容器以及针对搜索推荐业务的高性能特征存储。
13
微信chubby
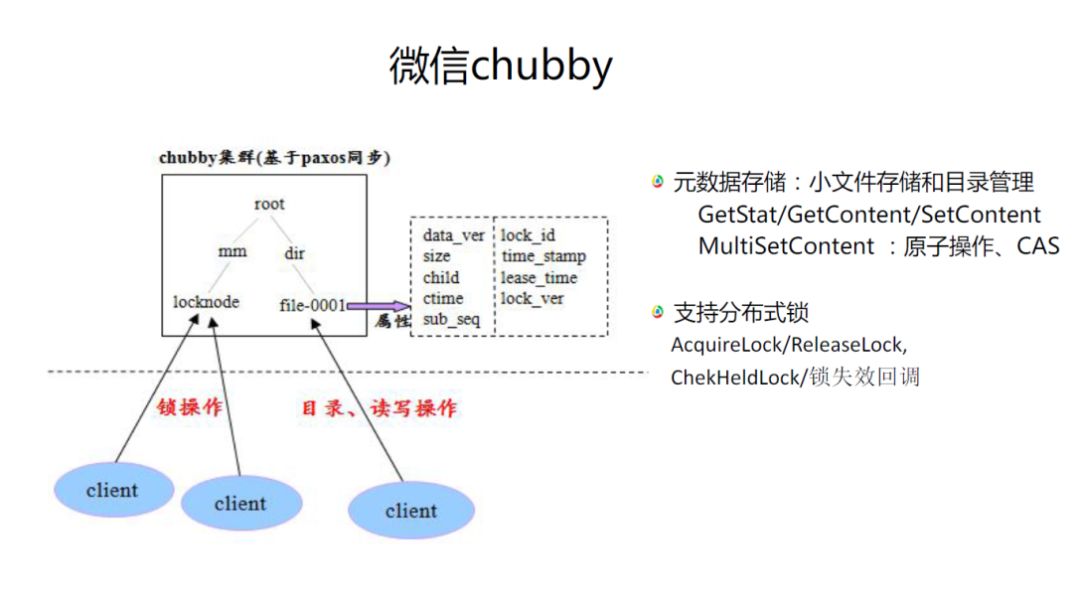
Chubby是Google一个论文提到的系统,我们也延伸了这样一个逻辑,基本上跟它的接口是一样的。
当时,我们有一个很奇怪的发现,不管是Google Chubby论文提到的代码量还是zookeeper的实际代码量都很大,但有了PaxosStore之后,根本不需要那么多的代码,所以接下来我们的处理也可能会考虑开源。
然后,我们基于PaxosStore也实现了分布式文件存储。
14
微信分布式文件系统
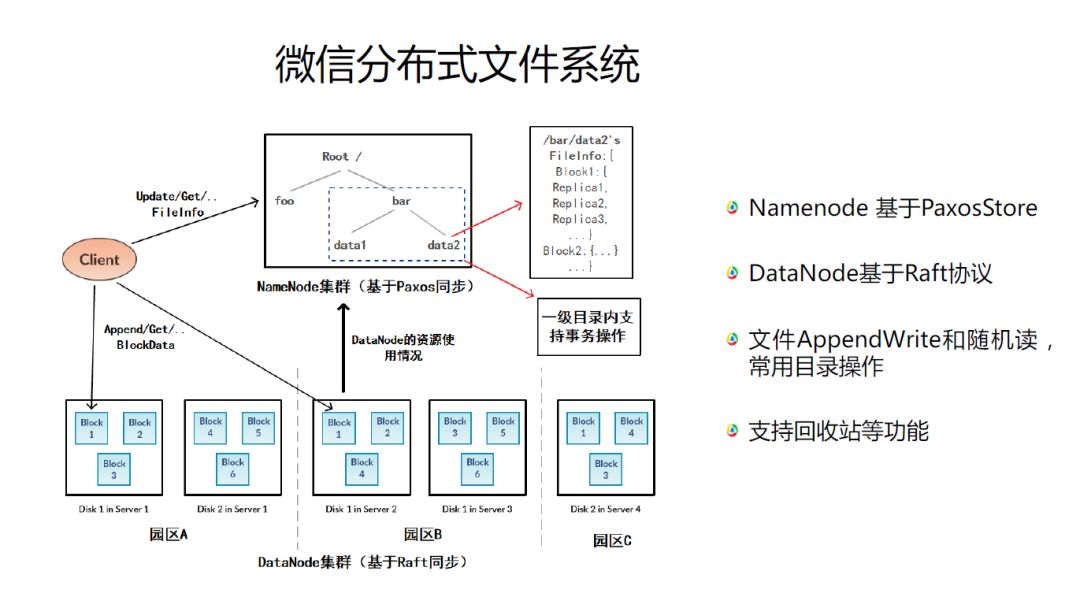
微信分布式文件系统Namenode 基于PaxosStore,DataNode基于Raft协议。Raft是基于租约机制的完美实现。基于Raft我们可以做到DataNode的强一致写。另外,它支持文件AppendWrite和随机读以及文件回收等功能。
15
分布式表格:架构图
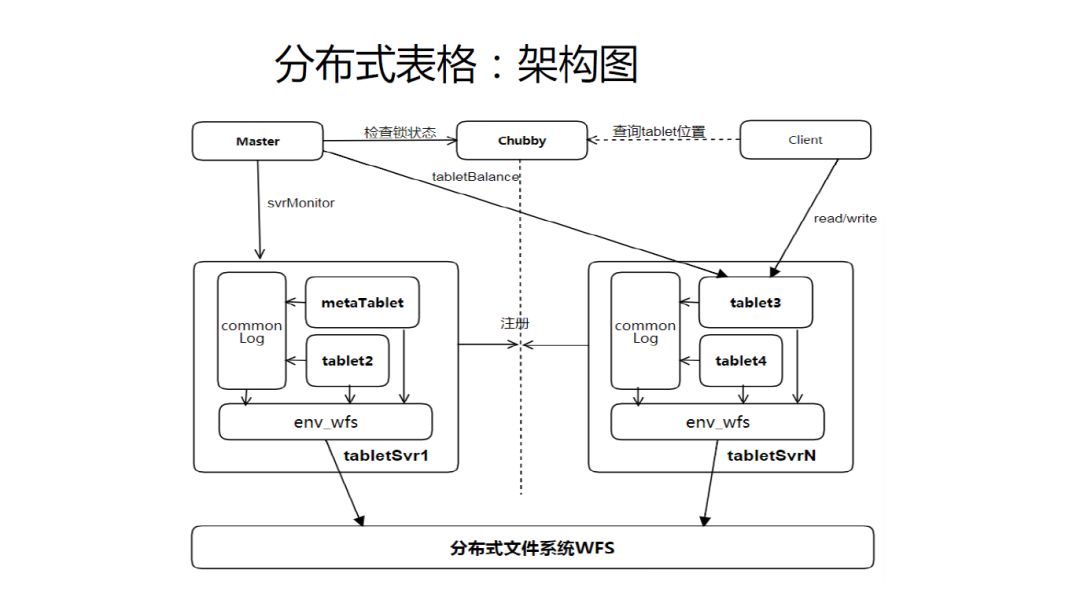
这个其实对应的是hbase。我们也基于PaxosStore去做了它的核心部分,然后把整套实现起来。
16
微服务框架
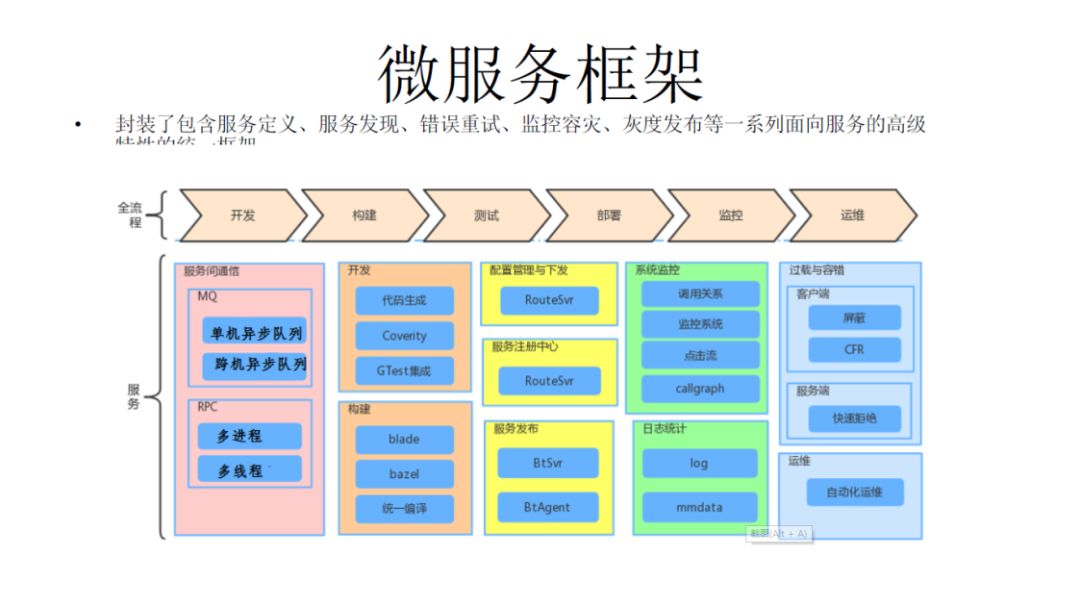
我们数据存储跟微服务架构是两大块。微服务包含了服务定义、服务发现、错误重试、监控容灾、灰度发布等一系列面向服务的高级特性的统一框架。中间有一个配置管理和下发的过程,这一块也是PaxosStore实现的,它可以完全控制代码的安全性。
下面是一个发布的过程,因为微信有很多台服务器,之前我们也有一个资源化系统,有可能一个服务会横跨几千台机器,这时候,发布一个二进制,只能在几百兆时间内,所以,内部也是一套BT协议。
然后,我们有一些监控处理,最后我们会有过载保护保护,在系统里面过载保护是很关键的一块。因为在后台,当一个请求过来的时候,某些节点产生了一个慢延迟和性能差,就会影响整条链路,所以我们会有一个整套的过载保护的实现。
17
业务逻辑Worker模型选择
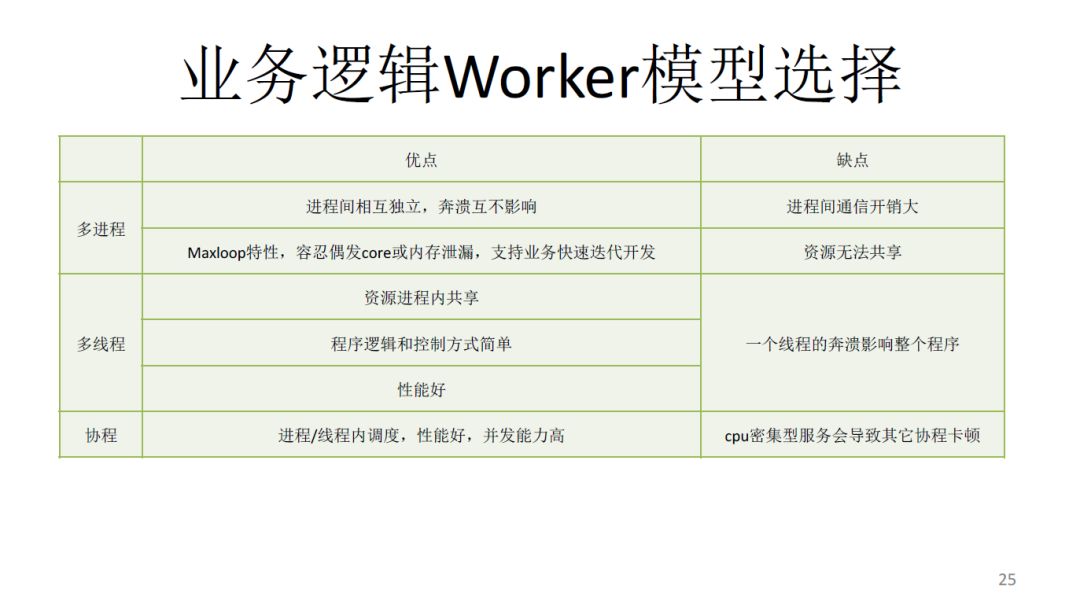
一般开源的东西就是在对标谁的性能高,但是在实际的后台服务当中,你的可用性要求都会很高。
所以我们会分成两种不同的服务,PaxosStore是比较重要的核心服务,使用多线程。但是在大量的应用开发中,我们始终是多进程的服务,而且多进程框架是可以定时重启的。
多进程的一个重点就在于内存泄漏与coredump容忍度很高,在快速开发特性时候尤其重要。
最后,不管是多进程还是多线程,都类似一个协程的处理,可以把我们的并发能力提得很高。
18
Libco背景
协程是在2013、2014年开始构建的。2013年,开始运行在微信的后台。基于2013年的那一次故障, 我们开始整体优化微信后台的过载保护能力,也促使我们去提升整个微信后台的高并发能力。
思考了几个月后,总结两个方法,一个是把整个代码逐步重构成一个异步模型,但这个工程量巨大。第二个是,去探索协程解决方案,少量修改代码达到同步编码,异步执行效果。但当时采取这个方案的案例不太多,所以,我们也很担心。
举个例子,如果把Leveldb的本地文件切换为远程文件系统,那么异步代码如何实现?协程如何实现?
19
异步服务与协程服务的对比
传统基于事件驱动的异步网络服务优势高、性能高、CPU利用率高,但编写困难,需要业务层维护状态机,业务逻辑被异步编码拆分得支离破碎。Future/promise等技术,趋近于同步编程,但仍然繁琐,并且并发任务难以编写与维护。
协程服务,同步编程、异步执行,由于不需要自己设计各种状态保存数据结构,临时状态/变量在一片连续的栈中分配,性能比手写异步通常要高,重要的一点是编写并发任务很方便。
20
协程定义

协程到底是什么?可以说它是微线程,也可以说它是用户态线程。协程切换流程其实不复杂,它主要任务是把上下文保存起来。上下文只有两个部分,第一部分是内存和寄存器,第二部分是栈的状态。
21
函数调用的基本原理
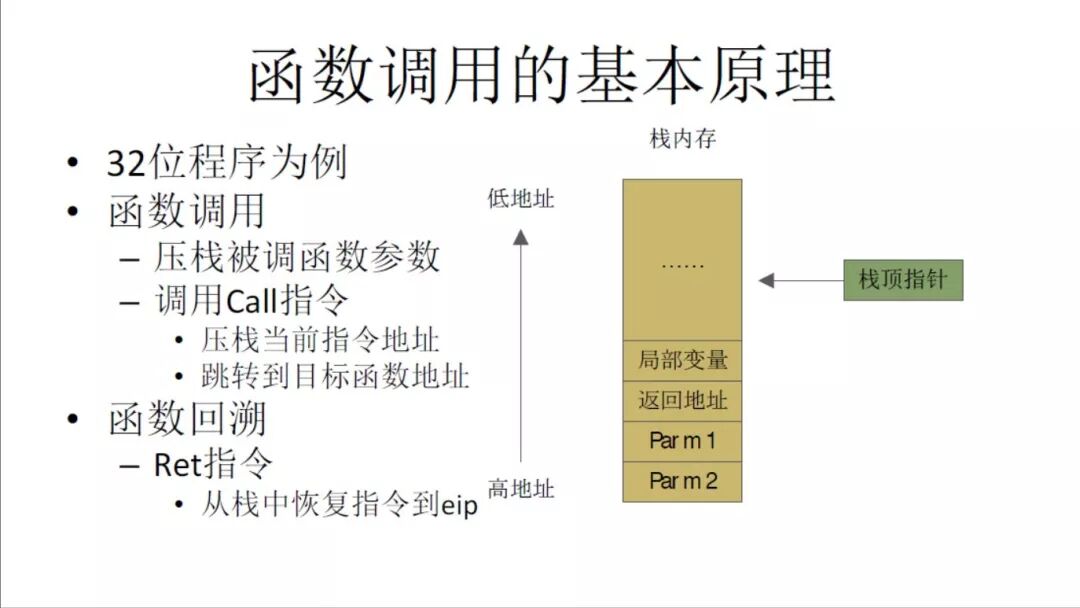
我们看一下函数调用的基本原理,32位程序为例的话,其实函数调用的过程很简单,就是把函数压栈,用Call指令跳到某个地方。因为eip不能直接修改,所以只能间接操作。Ret指令跟这个比较类似。
22
Libco协程切换核心代码
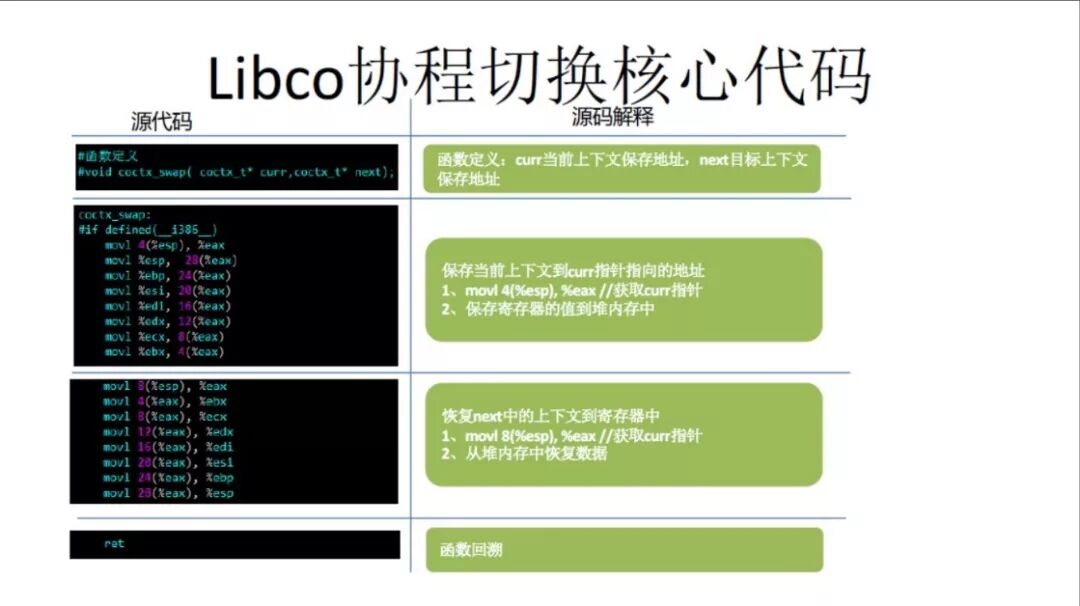
这是主要的代码。协程本身并不复杂,一个是因为基于上述的原理只要一些汇编代码可以了,它主要保存了一些寄存器,并把一些状态存起来,然后只处理一些寄存器的状态就可以。但只有这一部分是不够的,因为如果我们提供了一个协程,用户还是要做很多代码。
23
Libco框架
一个纯粹的协程必须跟网络框架结合在一起才能实现它的价值。
我们对协程做了最基本的源语,因为我们并不想发明更多的概念出来。协程的源语包括co_create/co_resume/co_yield,协程间同步cond/signal。
同时我们还提供了一个轻量级网络事件库。基于同样的考虑,这个库是基于epoll的事件回调以及基于时间轮盘的定时器设计。
另外Socket族函数hook,我们实现网络读写api hook,支持mysqlclient/gethostbyname,支持aio读磁盘,支持cgi(getenv/setenv)。
经过这套设计之后,我们就开始对微信的后台进行改造,目前基本上改造完成。
24
线程内协程切换图
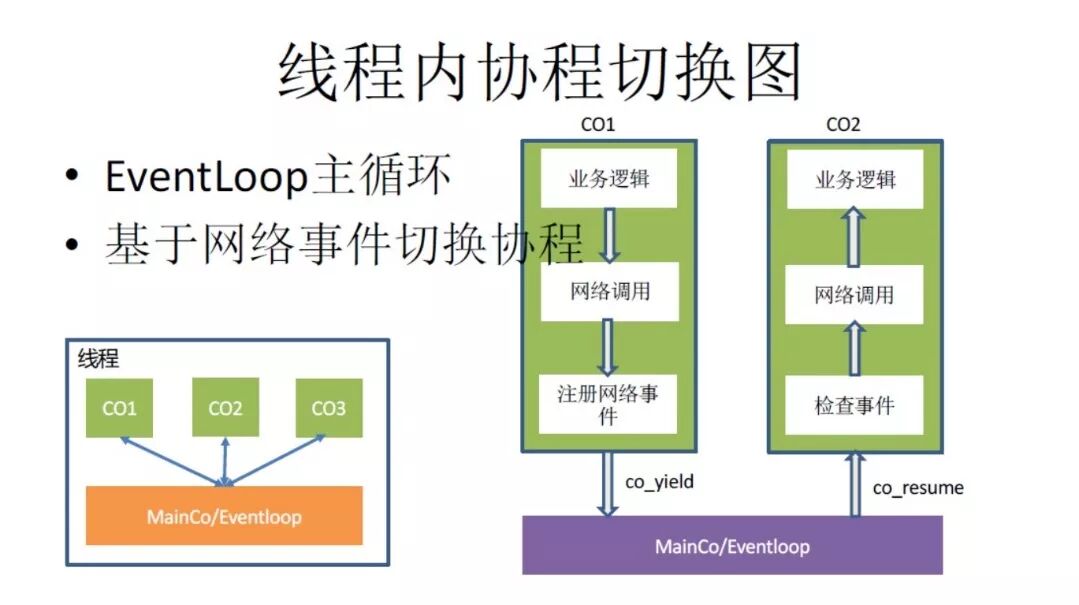
这是一些具体的情况。我们可以看到,我们必须实现一个主的EventLoop去处理后发出的所有事件,在事件被触发的时候,可以保证为通。
用一个标准的线程,基于网络事件切换协程。如果异步处理才能把逻辑分成很多分片,然后在事件触发过程中用回调来完成你的逻辑,但是反过来在协程里面就简单很多。
25
Libco下编程需要注意的点
现在Libco栈大小默认设置为128K,它可以支持一个共享执行,支持单机千万协程,那需要注意什么呢?有两点:
首先需要用poll代替sleep,其次对于计算较重的服务,需要分离计算线程与网络线程,避免互相影响。
在实践的过程中,遇到的问题还有很多,只要把所有的情况都考虑进去,就可能有很好的提升。这些年,有了这两大基础组件的支撑,微信现在进入比较稳定的时期。
今天分享大概就是这样,谢谢大家。
许家滔,微信技术架构部后台总监,专家工程师,多年来伴随QQ邮箱和微信后台成长,历经系统从0到10亿级用户的过程。目前负责微信后台工作,包括消息,资料与关系链,后台基础设施等内容。
本文根据许家滔老师在2018年10月17日【第十届中国系统架构师大会(SACC2018)】现场演讲内容整理而成。
01
回顾微信发展历程
2011年,我们发布了第一版微信,2012年,推出视频聊天功能。如今,微信的活跃用户数已经达到10亿。后台涉及到的技术很多,我这边主要聚焦于数据存储、微服务等。
02
微信后台系统架构
这是最新的微信后台系统架构图,逻辑上最前面会有一个终端,后面会有一个长链接接入层,在线有几亿的管理连接部分。底层上,因为数据比较敏感而且数据量比较大,所以我们的存储并没有基于开源来搭建,而是自己开发了一整套存储,这也是迭代比较多的部分。
最开始,也就是2011年,我们用的是第一代存储。早期的微信与QQ不同,它更像是一个邮箱。
这几年,我们逐渐完善,包括内部安全、管理等。
目前,我们最关心的有两个方面,一是高可用。微信作为一个国民应用,对高可用有着极高的要求,是不可以停顿的。早期的微信迭代速度很快,几乎每两周一个版本,还包括大量的修改。二是敏捷开发的一些问题。例如内存泄露、Coredump等。
03
数据业务背景与挑战
接下来,我重点讲一下数据存储和微服务框架这两块。今天的微信,用户数达10亿,每天的微信消息达1000+亿,朋友圈每日发表和点赞数达10+亿,每日浏览数达100+亿,开放平台,微信支付等业务活跃度持续增长。
总结成如下四大挑战:
1.海量存储
我们需要一个能容错、容灾的高可用存储与计算的框架;
2.数据强一致性
保障10亿用户数据不会出现问题;
3.突发洪峰流量
圣诞节、元旦、除夕以及突发热点事件;
4.后台数据服务节点每分钟超过百亿次数据存取服务;
04
目标
关于可用性,大家可能已经很熟悉了,这里我再细化一下。
最下面的2个9,是指一年故障时间不超过3.65天;最上面5个9 ,是指金融应用,一年故障时间不超过5分钟。
那么微信是一个什么样的应用呢?微信包含了金融应用,也就是大家常用的微信支付。
那么我们希望达到怎样的目标呢?有两大点:
1、机器故障是常态,微信希望提供连续无间断的服务能力
业界数据可用性通常通过RAFT,Paxos租约等来实现数据复制
机器故障时,系统会进入等待租约过期并重新选主的状态,即会产生30秒级别的服务中断,我们希望能够规避。
2、相对于传统的基于故障转移的系统设计,我们需要构建一个多主同时服务的系统
系统始终在多个数据中心中运行
数据中心之间自适应地移动负载
透明地处理不同规模的中断(主机,机房,城市园区等)
05
关键设计
微信关键技术演变。最初,微信是异步复制,比较传统的一个场景。中间这部分是选主同步复制。
业界有两种比较经典的系统:一种是基于故障切换的系统,包括两个主要的协议,Raft协议和基于租约Paxos Log。来保证数据的一致性,但对服务的可用性有一定影响。另一种是基于多主的系统,是在可用性方面做的最彻底的系统。它是基于非租约Paxos Log,Google MegaStore以及微信PaxosStore。
多主系统有很多的难点。第一, 海量Paxos Log管理,对存储引擎的要求很高;第二,代码假设在一个cas环境中运行。
要做到服务随时可用,对cache和热点处理的要求很高。同时它对于追流水/恢复流程有时效性的要求。
06
多主系统的收益
多主系统收益很大,可以分为几个点。
一是7×24小时的可用性,它可以应对有计划和无计划的停机维护。不再有封尘已久的切换流程,由于多主可用,类似快照与数据对齐等行为,已经在在线核心逻辑中充分体现。其次是变更发布,因为这些系统写出来并非一直不变,最大的可用性需求是来自于我们的程序版本发布。
第二点是资源调度,当系统变多主之后,相当于有了多台随时都可以用的机器,它们的模式都是一样的,为了回避弱的节点去使用更多计算资源,只要切流量就可以了。所以切存储跟切逻辑是一样的,统称为切流量。
最后一点是成本,多主系统的预留冗余成本是相对低的,因为所有的机器都可以服务用户,所以在多主系统方面我们只需预留1/3的成本即可。
07
设计与实践
微信的设计主要分为三大块:
第一,实现同步复制,在数据分区内部实现完整ACID语义,维护细粒度的海量数据分区,且每一次数据读写都基于非租约的Paxos交互实现,每分钟超过百亿次。
第二,存储引擎方面,针对微信丰富的业务场景,设计多种高性能的存储模型,其次,我们还支持单表过亿行的二维表格/FIFO队列/key-value等数据结构。
第三,负载均衡方面,我们希望存储系统可以动态切换计算资源,数据节点动态计算负载能力尽力服务,超过服务能力部分自动转移到其他复制节点。
08
实际成果
目前微信的实际成果,核心数据存储服务可用性达6个9。整个系统有一个创新的技术点,具体细节我们发表在:
http://www.vldb.org/pvldb/vol10/p1730-lin.pdf
论文相关示例代码开源:github.com/tencent/paxosstore。
早期大家对Paxos算法都是认为很难实现的,近两年逐渐有一些公司开始对这方面有一些分享。上面提到的这个论文是微信PaxosStore的一点创新,贡献出了一些简洁的算法实现流程,大家可以很轻松的去理解和实现。
09
PaxosStore广泛支持微信在线应用
这些数据的应用基本都是PaxosStore在支持。
10
PaxosStore整体架构
下面,简单介绍下PaxosStore的整体架构。
分成几个园区,园区必须有独立的网络和电力。 举个例子,假设有些机房实际上共享了一套电力甚至交换机的话,只要单点故障一样会挂掉。
所以,园区只是一个概念,至少要满足网络和电力独立,然后在考虑跨层或跨省的问题,PaxosStore实际上也有跨华东,华南,华北三个遥远距离的服务。
中间我们会把PaxosStore共识层和计算层、存储层分离起来,PaxosStore其实是一整套框架,它可以容纳不同的共识算法和存储。
下面是一个存储引擎。微信的存储引擎包括很多种,最早是Bitcask模型,现在广泛使用的是LSM,它可以支持比较多的业务。
最下面是迁移系统、备份系统、路由中心。
PaxosStore支持类SQL的filter,format,limit,groupby等能力,单表可以支持亿行记录。下一步,我们可能会根据业务的需求去开展。
11
PaxosStore:数据分布与复制
这一套分布式,其实是延伸了之前老系统的分布方式,数据会分成两层,它会按一致性hash划分到不同的节点。每个节点都有六个节点,它们交叉实现了复制的逻辑,可以达到一个比较好的负载均衡。
12
基于PaxosStore的在线基础组件
2017年之后,将整个微信90%的存储切完后,继续往下发展。随着业务的发展,我们把很多的立体图连起来。有了PaxosStore框架之后,很多系统都相对容易实现,像比较典型的zookeeper、hdfs、hbase等。
除了基本的数据系统之外,我们还有很多特殊的场景,例如远距离跨省常量存储。如,微信支付订单等场景,都有强烈的数据库需求,而且需要跨省容灾。
什么是远距离?考虑到故障的实际影响范围以及专线的物理情况,在地点的选择上,是有一定要求的,因此,在选点的选择上,一般选在整个中国跨越比较远的一些地方,如,上海、深圳、天津,构成了一个三角,相互间距大概2000公里左右。但有个实际问题,如果跨省,必须给它大概三四十毫秒左右的延迟。另外,像深圳跟汕头,上海跟天津,这些都不算远距离跨省。如果上海挂了,杭州的线也一定会出现问题,因为它俩距离比较近。
常量存储有什么特点?它的写需要有跨越三四十毫秒的跨城通信过程,但读是本地的。
另外,我们还针对微信支付复杂业务定制了事务容器以及针对搜索推荐业务的高性能特征存储。
13
微信chubby
Chubby是Google一个论文提到的系统,我们也延伸了这样一个逻辑,基本上跟它的接口是一样的。
当时,我们有一个很奇怪的发现,不管是Google Chubby论文提到的代码量还是zookeeper的实际代码量都很大,但有了PaxosStore之后,根本不需要那么多的代码,所以接下来我们的处理也可能会考虑开源。
然后,我们基于PaxosStore也实现了分布式文件存储。
14
微信分布式文件系统
微信分布式文件系统Namenode 基于PaxosStore,DataNode基于Raft协议。Raft是基于租约机制的完美实现。基于Raft我们可以做到DataNode的强一致写。另外,它支持文件AppendWrite和随机读以及文件回收等功能。
15
分布式表格:架构图
这个其实对应的是hbase。我们也基于PaxosStore去做了它的核心部分,然后把整套实现起来。
16
微服务框架
我们数据存储跟微服务架构是两大块。微服务包含了服务定义、服务发现、错误重试、监控容灾、灰度发布等一系列面向服务的高级特性的统一框架。中间有一个配置管理和下发的过程,这一块也是PaxosStore实现的,它可以完全控制代码的安全性。
下面是一个发布的过程,因为微信有很多台服务器,之前我们也有一个资源化系统,有可能一个服务会横跨几千台机器,这时候,发布一个二进制,只能在几百兆时间内,所以,内部也是一套BT协议。
然后,我们有一些监控处理,最后我们会有过载保护保护,在系统里面过载保护是很关键的一块。因为在后台,当一个请求过来的时候,某些节点产生了一个慢延迟和性能差,就会影响整条链路,所以我们会有一个整套的过载保护的实现。
17
业务逻辑Worker模型选择
一般开源的东西就是在对标谁的性能高,但是在实际的后台服务当中,你的可用性要求都会很高。
所以我们会分成两种不同的服务,PaxosStore是比较重要的核心服务,使用多线程。但是在大量的应用开发中,我们始终是多进程的服务,而且多进程框架是可以定时重启的。
多进程的一个重点就在于内存泄漏与coredump容忍度很高,在快速开发特性时候尤其重要。
最后,不管是多进程还是多线程,都类似一个协程的处理,可以把我们的并发能力提得很高。
18
Libco背景
协程是在2013、2014年开始构建的。2013年,开始运行在微信的后台。基于2013年的那一次故障, 我们开始整体优化微信后台的过载保护能力,也促使我们去提升整个微信后台的高并发能力。
思考了几个月后,总结两个方法,一个是把整个代码逐步重构成一个异步模型,但这个工程量巨大。第二个是,去探索协程解决方案,少量修改代码达到同步编码,异步执行效果。但当时采取这个方案的案例不太多,所以,我们也很担心。
举个例子,如果把Leveldb的本地文件切换为远程文件系统,那么异步代码如何实现?协程如何实现?
19
异步服务与协程服务的对比
传统基于事件驱动的异步网络服务优势高、性能高、CPU利用率高,但编写困难,需要业务层维护状态机,业务逻辑被异步编码拆分得支离破碎。Future/promise等技术,趋近于同步编程,但仍然繁琐,并且并发任务难以编写与维护。
协程服务,同步编程、异步执行,由于不需要自己设计各种状态保存数据结构,临时状态/变量在一片连续的栈中分配,性能比手写异步通常要高,重要的一点是编写并发任务很方便。
20
协程定义
协程到底是什么?可以说它是微线程,也可以说它是用户态线程。协程切换流程其实不复杂,它主要任务是把上下文保存起来。上下文只有两个部分,第一部分是内存和寄存器,第二部分是栈的状态。
21
函数调用的基本原理
我们看一下函数调用的基本原理,32位程序为例的话,其实函数调用的过程很简单,就是把函数压栈,用Call指令跳到某个地方。因为eip不能直接修改,所以只能间接操作。Ret指令跟这个比较类似。
22
Libco协程切换核心代码
这是主要的代码。协程本身并不复杂,一个是因为基于上述的原理只要一些汇编代码可以了,它主要保存了一些寄存器,并把一些状态存起来,然后只处理一些寄存器的状态就可以。但只有这一部分是不够的,因为如果我们提供了一个协程,用户还是要做很多代码。
23
Libco框架
一个纯粹的协程必须跟网络框架结合在一起才能实现它的价值。
我们对协程做了最基本的源语,因为我们并不想发明更多的概念出来。协程的源语包括co_create/co_resume/co_yield,协程间同步cond/signal。
同时我们还提供了一个轻量级网络事件库。基于同样的考虑,这个库是基于epoll的事件回调以及基于时间轮盘的定时器设计。
另外Socket族函数hook,我们实现网络读写api hook,支持mysqlclient/gethostbyname,支持aio读磁盘,支持cgi(getenv/setenv)。
经过这套设计之后,我们就开始对微信的后台进行改造,目前基本上改造完成。
24
线程内协程切换图
这是一些具体的情况。我们可以看到,我们必须实现一个主的EventLoop去处理后发出的所有事件,在事件被触发的时候,可以保证为通。
用一个标准的线程,基于网络事件切换协程。如果异步处理才能把逻辑分成很多分片,然后在事件触发过程中用回调来完成你的逻辑,但是反过来在协程里面就简单很多。
25
Libco下编程需要注意的点
现在Libco栈大小默认设置为128K,它可以支持一个共享执行,支持单机千万协程,那需要注意什么呢?有两点:
首先需要用poll代替sleep,其次对于计算较重的服务,需要分离计算线程与网络线程,避免互相影响。
在实践的过程中,遇到的问题还有很多,只要把所有的情况都考虑进去,就可能有很好的提升。这些年,有了这两大基础组件的支撑,微信现在进入比较稳定的时期。
今天分享大概就是这样,谢谢大家。
作者:许家滔
编辑:老鱼,公众号老鱼笔记(id:laoyubiji)
本篇文章为 @ 21CTO 创作并授权 21CTO 发布,未经许可,请勿转载。
内容授权事宜请您联系 webmaster@21cto.com或关注 21CTO 微信公众号。
该文观点仅代表作者本人,21CTO 平台仅提供信息存储空间服务。
评论
21CTO
管理团队最新文章
我要赞赏作者
请扫描二维码,使用微信支付哦。