{kind=link}
【第915期】从Chrome源码看JS Array的实现
前言
昨天是不是看了一篇类短篇小说呢,非常详细的一篇。四月份最后一周,周末就是五一节了。今日早读文章由@李银城分享。
正文从这开始~
在此之前,笔者将Chromium升级到了最新版本60,上一次是在元旦的时候下的57,而当前最新发布的稳定版本是57。57是三月上旬发布的,所以Chrome发布一个大版本至少用了两、三个月的时间。Chrome 60的devTool增加了很多有趣的功能,这里顺便提一下:
例如把没有用到的CSS/JS按比例标红,增加了全页的截屏功能,和一个本地代码的编辑器:
JS的Array是一个万能的数据结构,为什么这么说呢?因为首先它可以当作一个普通的数组来使用,即通过下标找到数组的元素:
var array = [19, 50, 99];
console.log(array[0]);
然后它可以当作一个栈来使用,我们知道栈的特点是先进后出,栈的基本操作是出栈和入栈:
var stack = [1, 2, 3];
stack.push(4); //入栈
var top = stack.pop(); // 出栈
同时它还可以当作一个队列,队列的特点是先进先出,基本操作是出队和入队:
var queue = [1, 2, 3];
queue.push(4); //入队
var head = queue.shift(); // 出队
甚至它还可以当作一个哈希表来使用(但是不推荐这么用):
var map = [];
map["id"] = 1234;
map["name"] = "yin";
console.log(map["name"]);
另外,它还可以随时随地增删数组中任意位置的元素:
var array = [1, 2, 3, 4];
//从第3个元素开始,删掉1个元素,并插入-1,-2这两个元素
array.splice(2, 1, -1, -2);
//再来个2000的索引
array[2000] = 10;
JS Array一方面提供了很大的便利,只要用一个数据结构就可以做很多事情,使用者不需要关心各者的区别,使得JS很容易入门。另一方面它屏蔽了数据结构的概念,不少写前端的都不知道什么是栈、队列、哈希、树,特别是那些不是学计算机,中途转过来的。然而这往往是不可取的。
另外一点是,即使是一些前端的老司机,他们也很难说清楚,这些数组函数操作的效率怎么样,例如说随意地往数组中间增加一个元素不会有性能问题么。所以就很有必要从源码的角度看一下数组是怎么实现的。
1. JS Array的实现
先看源码注释:
// The JSArray describes JavaScript Arrays
// Such an array can be in one of two modes:
// - fast, backing storage is a FixedArray and length <= elements.length();
// Please note: push and pop can be used to grow and shrink the array.
// - slow, backing storage is a HashTable with numbers as keys.
class JSArray: public JSObject {
public:
// [length]: The length property.
DECL_ACCESSORS(length, Object)
// Number of element slots to pre-allocate for an empty array.
static const int kPreallocatedArrayElements = 4;
};
这里说明一下,如果不熟悉C/C++的,那把它成伪码就好了。
源码里面说了,JSArray有两种模式,一种是快速的,一种是慢速的,快速的用的是索引直接定位,慢速的使用用哈希查找,这个在上一篇《从Chrome源码看JS Object的实现》就已经提及,由于JSArray是继承于JSObject,所以它也是同样的处理方式,如下面的:
var array = [1, 2, 3]
array[2000] = 10;
增加一个2000的索引时,array就会被转成慢元素。
如下的数组:
var a = [8, 1, 2];
把a打印出来:
- map = 0x939ebe04359 [FastProperties]
- prototype = 0x27e86e126289
- elements = 0xe70c791d4e9 <FixedArray[3]> [FAST_SMI_ELEMENTS (COW)]
- length = 3
- properties = 0x2b609d202241 <FixedArray[0]> {
#length: 0x2019c3e58da9 <AccessorInfo> (const accessor descriptor)
}
- elements= 0xe70c791d4e9 <FixedArray[3]> {
0: 8
1: 1
2: 2
}
打印出来的array 变成:
- map = 0x333c83f9dbb9 [FastProperties]
- prototype = 0xdcc53ba6289
- elements = 0x21a208a1d541 <FixedArray[29]> [DICTIONARY_ELEMENTS]
- length = 2001
- properties = 0x885d1402241 <FixedArray[0]> {
#length: 0x1f564a958da9 <AccessorInfo> (const accessor descriptor)
}
- elements= 0x21a208a1d541 <FixedArray[29]> {
2: 2 (data, dict_index: 0, attrs: [WEC])
0: 8 (data, dict_index: 0, attrs: [WEC])
2000: 10 (data, dict_index: 0, attrs: [WEC])
1: 1 (data, dict_index: 0, attrs: [WEC])
}
elements变成了一个慢元素哈希表,哈希表的容量为29。
由于快元素和慢元素上一节已经有详细讨论,这一节将不再重复。我们重点讨论数组的操作函数的实现。
2. Push和扩容
数组初始化大小为 4:
// Number of element slots to pre-allocate for an empty array.
static const int kPreallocatedArrayElements = 4;
执行push的时候会在数组的末尾添加新的元素,而一旦空间不足时,将进行扩容。
在源码里面push是用汇编实现的,在C++里面嵌入的汇编。这个应该是考虑到push是一个最为常用的操作,所以用汇编实现提高执行速度。在汇编的上面封装了一层,用C++调的封装的汇编的函数,在编译组装的时候,将把这些C++代码转成汇编代码。
计算新容量的函数:
Node* CodeStubAssembler::CalculateNewElementsCapacity(Node* old_capacity,
ParameterMode mode) {
Node* half_old_capacity = WordOrSmiShr(old_capacity, 1, mode);
Node* new_capacity = IntPtrOrSmiAdd(half_old_capacity, old_capacity, mode);
Node* padding = IntPtrOrSmiConstant(16, mode);
return IntPtrOrSmiAdd(new_capacity, padding, mode);
}
如上代码新容量等于 :
Node* CodeStubAssembler::GrowElementsCapacity(
Node* object, Node* elements, Node* capacity, Node* new_capacity) {
// Allocate the new backing store.
Node* new_elements = AllocateFixedArray(new_capacity, mode);
// Copy the elements from the old elements store to the new.
CopyFixedArrayElements(elements, new_elements, capacity, new_capacity);
return new_elements;
}
由于复制是用的memcopy,把整一段内存空间拷贝过去,所以这个操作还是比较快的。
再把新元素放到当前length的位置,再把length 增加 1:
StoreFixedArrayElement(elements, var_length.value());
Increment(var_length, 1, mode);
可以来改点代码玩玩,我们知道push执行后的返回结果是新数组的长度,尝试把它改成返回老数组的长度:
Node *old_length = LoadJSArrayLength(receiver);
Node *new_length = BuildAppendJSArray(/.../);
//args.PopAndReturn(new_length);
args.PopAndReturn(old_length);
重新编译Chrome,在控制台上执行比较如下:

右边的新Chrome返回了4,左边正常的Chrome返回5.
3. Pop和减容
push是用汇编实现,而pop的逻辑是用C++写的。在执行pop的时候,第一步,获取到当前的length,用这个length - 1得到要删除的元素,然后调用setLength调整容量,最后返回删除的元素:
int new_length = length - 1;
int remove_index = remove_position == AT_START ? 0 : new_length;
Handle<Object> result =
Subclass::GetImpl(isolate, *backing_store, remove_index);
Subclass::SetLengthImpl(isolate, receiver, new_length, backing_store);
return result;
我们重点看下这个减容的过程:
if (2 * length <= capacity) {
// If more than half the elements won't be used, trim the array.
isolate->heap()->RightTrimFixedArray(*backing_store, capacity - length);
} else {
// Otherwise, fill the unused tail with holes.
BackingStore::cast(*backing_store)->FillWithHoles(length, old_length);
}
如果容量大于等于length的2倍,则进行容量调整,否则用holes对象填充。第三行的rightTrim函数,会算出需要释放的空间大小,并做标记,并等待GC 回收:
int bytes_to_trim = elements_to_trim * element_size;
// Calculate location of new array end.
Address old_end = object->address() + object->Size();
Address new_end = old_end - bytes_to_trim;
CreateFillerObjectAt(new_end, bytes_to_trim, ClearRecordedSlots::kYes);
也就是说,当数组的元素个数小于容量的一半时,就会进行减少的操作,将容量调整为实际的大小。
4. shift和splice数组中间的操作
push和pop都是在数组末尾操作,相对比较简单,而shfit、unshfit、splice是在数组的开始或者中间进行操纵。我们来看一下,如果是这种情况的又是如何调整数组元素的。
(1)shift是出队,即删除并返回数组的第一个元素。shift和pop调的都是同样的删除函数,只不过shift传的删除的postion是AT_STRT,源码里面会判断如果是AT_START的话,会把元素进行移动:
if (remove_position == AT_START) {
Subclass::MoveElements(isolate, receiver, backing_store, 0, 1, new_length,
0, 0);
}
从1的位置移到0的位置,如上面第2行的第4、5个参数,这个move将会调leftTrim,和上面的rightTrim 相反:
*dst_elms.location() =
BackingStore::cast(heap->LeftTrimFixedArray(*dst_elms, src_index));
receiver->set_elements(*dst_elms);
(2)unshfit在数组的开始位置插入元素,首先要判断容量是否足够存放,如果不够,将容量扩展为老容量的1.5倍加16,然后把老元素移到新的内存空间偏移为unshift元素个数的位置,也就是说要腾出起始的空间放unshfit传进来的元素,如果空间足够了,则直接执行memmove移动内存空间,最后再把unshif传进来的参数copy到开始的位置:
int insertion_index = add_position == AT_START ? 0 : length;
// Copy the arguments to the start.
Subclass::CopyArguments(args, backing_store, add_size, 1, insertion_index);
// Set the length.
receiver->set_length(Smi::FromInt(new_length));
并更新array的length。
(3)splice的操作已经几乎不用去看源码了,通过shift和unshift的操作是怎么样的,就可以想象到它的执行过程是怎样的,只是shift/unshfit操作的index是0,而splice可以指定index。具体代码如下:
// Delete and move elements to make space for add_count new elements.
if (add_count < delete_count) {
Subclass::SpliceShrinkStep(isolate, receiver, backing_store, start,
delete_count, add_count, length, new_length);
} else if (add_count > delete_count) {
backing_store =
Subclass::SpliceGrowStep(isolate, receiver, backing_store, start,
delete_count, add_count, length, new_length);
}
// Copy over the arguments.
Subclass::CopyArguments(args, backing_store, add_count, 3, start);
它需要先shrink或者grow中间元素的空间,以适应增加元素比删除元素少或者多的情况,然后进行容量调整和移动元素。
接着再来看下两个“小清新”的函数
5. Join和Sort
说它们是小清新,是因为它们是用JS实现的,然后再用wasm打包成native code。不过,join的实现逻辑并不简单,因为array的元素本身具有多样化,可能为慢元素或者快元素,还可能带有循环引用,对于慢元素,需要先排下序:
var keys = GetSortedArrayKeys(array, %GetArrayKeys(array, length));
预处理完之后,最后创建一个字符串数组,用连接符连起来:
// Construct an array for the elements.
var elements = new InternalArray(length);
for (var i = 0; i < length; i++) {
elements[i] = ConvertToString(use_locale, array[i]);
}
if (separator === '') {
return %StringBuilderConcat(elements, length, '');
} else {
return %StringBuilderJoin(elements, length, separator);
}
而sort函数是用的快速排序:
function ArraySort(comparefn) {
CHECK_OBJECT_COERCIBLE(this, "Array.prototype.sort");
%Log("js/array.js execute ArraySort"); //手动添加的log打印,确保执行的是这里
var array = TO_OBJECT(this);
var length = TO_LENGTH(array.length);
return InnerArraySort(array, length, comparefn);
}
当数组元素的个数不超过10个时,是用的插入排序:
function InnerArraySort(array, length, comparefn) {
// In-place QuickSort algorithm.
// For short (length <= 10) arrays, insertion sort is used for efficiency.
function QuickSort(a, from, to) {
var third_index = 0;
while (true) {
// Insertion sort is faster for short arrays.
if (to - from <= 10) {
InsertionSort(a, from, to);
return;
}
//other code ...
}
}
}
快速排序算法里面有一个比较重要的地方是选择枢纽元素,最简单的是每次都是选取第一个元素,或者中间的元素,在源码里面是这样选择的:
if (to - from > 1000) {
third_index = GetThirdIndex(a, from, to);
} else {
third_index = from + ((to - from) >> 1);
}
如果元素个数在1000以内,则使用它们的中间元素,否则要算一下, 这个算法比较有趣:
function GetThirdIndex(a, from, to) {
var t_array = new InternalArray();
// Use both 'from' and 'to' to determine the pivot candidates.
var increment = 200 + ((to - from) & 15);
var j = 0;
from += 1;
to -= 1;
for (var i = from; i < to; i += increment) {
t_array[j] = [i, a[i]];
j++;
}
t_array.sort(function(a, b) {
return comparefn(a[1], b[1]);
});
var third_index = t_array[t_array.length >> 1][0];
return third_index;
}
先取一个递增间距200~215之间,再循环取出原元素里面落到这个间距的元素,放到一个新的数组里面(这个数组是C++里面的数组),然后排下序,取中间的元素。因为枢纽元素的刚好是所有元素的中位数时,排序的效果最好,而这里是取出少数元素的中位数,类似于抽样模拟,缺点是它得再借助另外的排序算法。
最后再比较一下Array和线性链接的速度。
6. Array和线性链接的速度
线性链接是一种非连续存储的数据结构,每个元素都有一个指针指向它的下一个元素,所以它删除元素的时候不需要移动其它元素,也不需要考虑扩容的事情,但是它的查找比较慢。我们实现一个简单的List和Array进行比较。
List的每个节点用一个Node 表示:
class Node{
constructor(value, next){
this.value = value;
this.next = next;
}
}
每个List都有一个头指针指向第一个元素,和一个length记录它的长度:
class List{
constructor(){
this.head = null;
this.tail = null;
this.length = 0;
}
}
然后实现它的push和unshift 函数:
class List{
unshift(value){
return this.insert(0, value);
}
push(value){
if(this.head === null){
this.head = new Node(value, this.tail);
this.length++;
} else {
this.insert(this.length, value);
}
return this.length;
}
}
两个函数都会调一个通用的insert 函数:
insert(index, value){
var insertPos = this.head;
//找到需要插入的位置的节点
for(var i = 0; i < index - 1; i++){
insertPos = insertPos.next;
}
var node = null;
if(index === 0){
node = new Node(value, this.head);
this.head = node;
} else {
node = new Node(value, insertPos.next);
insertPos.next = node;
}
this.length++;
return value;
}
有了这个List之后,就可以初始化一个list和array:
var list = new List();
var arr = [];
for(var i = 0; i < 100; i++){
list.push(i);
arr.push(i);
}
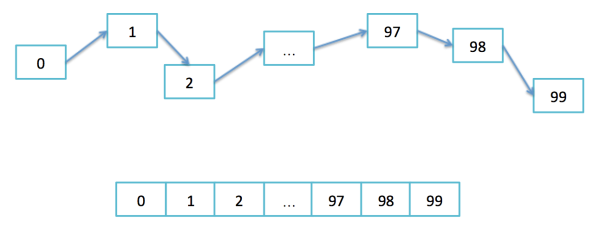
可以来比较这个List和Array的存储方式,非连续和连续的区别:
然后用下面的代码比较List和Array在数组起始位置插入元素的操作时间:
var count = 10000;
console.time("list unshfit");
for(var i = 0; i < count; i++){
list.unshift(i);
}
console.timeEnd("list unshfit");
console.time("array unshfit");
for(var i = 0; i < count; i++){
arr.unshift(i);
}
console.timeEnd("array unshfit");
再比较从正中间位置插入元素的时间:
console.time("list insert middle with index");
for(var i = 0; i < count; i++){
insertPos = list.insert(list.length >> 1, i);
}
console.timeEnd("list insert middle with index");
console.time("array insert middle");
for(var i = 0; i < count; i++){
arr.splice(arr.length >> 1, 0, i);
}
console.timeEnd("array insert middle");
运行可以得到以下表格:
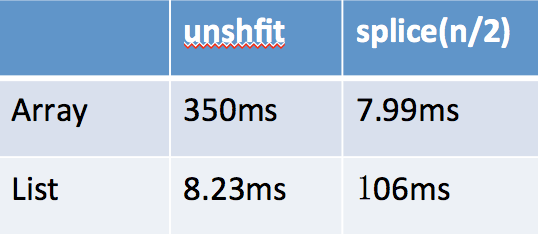
可以看到在队首插入元素,使用线性链接List的时间将会数量级的优于Array。如果是在中间位置插入的话,由于 List的查找花费了很多时间,导致总时间明显高于Array。但是如果在插入的时候,记住上一次的位置,那么List又会明显快于Array。如下换成记录插入的位置:
console.time("list insert middle with pos");
var insertPos = list.getNode(list.length >> 1);
for(var i = 0; i < count; i++){
insertPos = list.insertFromNode(insertPos, i);
}
console.timeEnd("list insert middle with pos");
时间比较List又快于Array:
综上,本文介绍了JS Array的实现,特别是它的操作函数,分析了它是怎么调整容量和移动元素的,并用了一个线性链接进行比较。Array的实现用了三种语言:汇编、C++和JS,最常用的如push用了汇编实现,比较常用的如pop/splice等用了C++,较为少用的如join/sort用了JS。
Array为快元素即普通的数组时,增删元素操作需要不断的扩容、减容和调整元素的位置。特别是当不断地在起始位置插入元素时,和链表相比,这种时间效率还是比较低下的。如果使用的场景是要根据index删除元素,使用Array还是有优势,但是若能够很快定位到删除元素的位置,链表毫无疑问是更合适的。
最后,他曾经分享过:
【第861期】从Chrome源码看浏览器如何计算CSS
【第901期】从Chrome源码看JS Object的实现
关于本文
作者:@李银城
原文:https://zhuanlan.zhihu.com/p/26388217

昨天是不是看了一篇类短篇小说呢,非常详细的一篇。四月份最后一周,周末就是五一节了。今日早读文章由@李银城分享。
正文从这开始~
在此之前,笔者将Chromium升级到了最新版本60,上一次是在元旦的时候下的57,而当前最新发布的稳定版本是57。57是三月上旬发布的,所以Chrome发布一个大版本至少用了两、三个月的时间。Chrome 60的devTool增加了很多有趣的功能,这里顺便提一下:
例如把没有用到的CSS/JS按比例标红,增加了全页的截屏功能,和一个本地代码的编辑器:
JS的Array是一个万能的数据结构,为什么这么说呢?因为首先它可以当作一个普通的数组来使用,即通过下标找到数组的元素:
var array = [19, 50, 99];
console.log(array[0]);
然后它可以当作一个栈来使用,我们知道栈的特点是先进后出,栈的基本操作是出栈和入栈:
var stack = [1, 2, 3];
stack.push(4); //入栈
var top = stack.pop(); // 出栈
同时它还可以当作一个队列,队列的特点是先进先出,基本操作是出队和入队:
var queue = [1, 2, 3];
queue.push(4); //入队
var head = queue.shift(); // 出队
甚至它还可以当作一个哈希表来使用(但是不推荐这么用):
var map = [];
map["id"] = 1234;
map["name"] = "yin";
console.log(map["name"]);
另外,它还可以随时随地增删数组中任意位置的元素:
var array = [1, 2, 3, 4];
//从第3个元素开始,删掉1个元素,并插入-1,-2这两个元素
array.splice(2, 1, -1, -2);
//再来个2000的索引
array[2000] = 10;
JS Array一方面提供了很大的便利,只要用一个数据结构就可以做很多事情,使用者不需要关心各者的区别,使得JS很容易入门。另一方面它屏蔽了数据结构的概念,不少写前端的都不知道什么是栈、队列、哈希、树,特别是那些不是学计算机,中途转过来的。然而这往往是不可取的。
另外一点是,即使是一些前端的老司机,他们也很难说清楚,这些数组函数操作的效率怎么样,例如说随意地往数组中间增加一个元素不会有性能问题么。所以就很有必要从源码的角度看一下数组是怎么实现的。
1. JS Array的实现
先看源码注释:
// The JSArray describes JavaScript Arrays
// Such an array can be in one of two modes:
// - fast, backing storage is a FixedArray and length <= elements.length();
// Please note: push and pop can be used to grow and shrink the array.
// - slow, backing storage is a HashTable with numbers as keys.
class JSArray: public JSObject {
public:
// [length]: The length property.
DECL_ACCESSORS(length, Object)
// Number of element slots to pre-allocate for an empty array.
static const int kPreallocatedArrayElements = 4;
};
这里说明一下,如果不熟悉C/C++的,那把它成伪码就好了。
源码里面说了,JSArray有两种模式,一种是快速的,一种是慢速的,快速的用的是索引直接定位,慢速的使用用哈希查找,这个在上一篇《从Chrome源码看JS Object的实现》就已经提及,由于JSArray是继承于JSObject,所以它也是同样的处理方式,如下面的:
var array = [1, 2, 3]
array[2000] = 10;
增加一个2000的索引时,array就会被转成慢元素。
如下的数组:
var a = [8, 1, 2];
把a打印出来:
- map = 0x939ebe04359 [FastProperties]
- prototype = 0x27e86e126289
- elements = 0xe70c791d4e9 <FixedArray[3]> [FAST_SMI_ELEMENTS (COW)]
- length = 3
- properties = 0x2b609d202241 <FixedArray[0]> {
#length: 0x2019c3e58da9 <AccessorInfo> (const accessor descriptor)
}
- elements= 0xe70c791d4e9 <FixedArray[3]> {
0: 8
1: 1
2: 2
}
打印出来的array 变成:
- map = 0x333c83f9dbb9 [FastProperties]
- prototype = 0xdcc53ba6289
- elements = 0x21a208a1d541 <FixedArray[29]> [DICTIONARY_ELEMENTS]
- length = 2001
- properties = 0x885d1402241 <FixedArray[0]> {
#length: 0x1f564a958da9 <AccessorInfo> (const accessor descriptor)
}
- elements= 0x21a208a1d541 <FixedArray[29]> {
2: 2 (data, dict_index: 0, attrs: [WEC])
0: 8 (data, dict_index: 0, attrs: [WEC])
2000: 10 (data, dict_index: 0, attrs: [WEC])
1: 1 (data, dict_index: 0, attrs: [WEC])
}
elements变成了一个慢元素哈希表,哈希表的容量为29。
由于快元素和慢元素上一节已经有详细讨论,这一节将不再重复。我们重点讨论数组的操作函数的实现。
2. Push和扩容
数组初始化大小为 4:
// Number of element slots to pre-allocate for an empty array.
static const int kPreallocatedArrayElements = 4;
执行push的时候会在数组的末尾添加新的元素,而一旦空间不足时,将进行扩容。
在源码里面push是用汇编实现的,在C++里面嵌入的汇编。这个应该是考虑到push是一个最为常用的操作,所以用汇编实现提高执行速度。在汇编的上面封装了一层,用C++调的封装的汇编的函数,在编译组装的时候,将把这些C++代码转成汇编代码。
计算新容量的函数:
Node* CodeStubAssembler::CalculateNewElementsCapacity(Node* old_capacity,
ParameterMode mode) {
Node* half_old_capacity = WordOrSmiShr(old_capacity, 1, mode);
Node* new_capacity = IntPtrOrSmiAdd(half_old_capacity, old_capacity, mode);
Node* padding = IntPtrOrSmiConstant(16, mode);
return IntPtrOrSmiAdd(new_capacity, padding, mode);
}
如上代码新容量等于 :
即老的容量的1.5倍加上16。初始化为4个,当push第5个的时候,容量将会变成:new_capacity = old_capacity /2 + old_capacity + 16
接着申请一块这么大的内存,把老的数据拷过去:new_capacity = 4 / 2 + 4 + 16 = 22
Node* CodeStubAssembler::GrowElementsCapacity(
Node* object, Node* elements, Node* capacity, Node* new_capacity) {
// Allocate the new backing store.
Node* new_elements = AllocateFixedArray(new_capacity, mode);
// Copy the elements from the old elements store to the new.
CopyFixedArrayElements(elements, new_elements, capacity, new_capacity);
return new_elements;
}
由于复制是用的memcopy,把整一段内存空间拷贝过去,所以这个操作还是比较快的。
再把新元素放到当前length的位置,再把length 增加 1:
StoreFixedArrayElement(elements, var_length.value());
Increment(var_length, 1, mode);
可以来改点代码玩玩,我们知道push执行后的返回结果是新数组的长度,尝试把它改成返回老数组的长度:
Node *old_length = LoadJSArrayLength(receiver);
Node *new_length = BuildAppendJSArray(/.../);
//args.PopAndReturn(new_length);
args.PopAndReturn(old_length);
重新编译Chrome,在控制台上执行比较如下:
右边的新Chrome返回了4,左边正常的Chrome返回5.
3. Pop和减容
push是用汇编实现,而pop的逻辑是用C++写的。在执行pop的时候,第一步,获取到当前的length,用这个length - 1得到要删除的元素,然后调用setLength调整容量,最后返回删除的元素:
int new_length = length - 1;
int remove_index = remove_position == AT_START ? 0 : new_length;
Handle<Object> result =
Subclass::GetImpl(isolate, *backing_store, remove_index);
Subclass::SetLengthImpl(isolate, receiver, new_length, backing_store);
return result;
我们重点看下这个减容的过程:
if (2 * length <= capacity) {
// If more than half the elements won't be used, trim the array.
isolate->heap()->RightTrimFixedArray(*backing_store, capacity - length);
} else {
// Otherwise, fill the unused tail with holes.
BackingStore::cast(*backing_store)->FillWithHoles(length, old_length);
}
如果容量大于等于length的2倍,则进行容量调整,否则用holes对象填充。第三行的rightTrim函数,会算出需要释放的空间大小,并做标记,并等待GC 回收:
int bytes_to_trim = elements_to_trim * element_size;
// Calculate location of new array end.
Address old_end = object->address() + object->Size();
Address new_end = old_end - bytes_to_trim;
CreateFillerObjectAt(new_end, bytes_to_trim, ClearRecordedSlots::kYes);
也就是说,当数组的元素个数小于容量的一半时,就会进行减少的操作,将容量调整为实际的大小。
4. shift和splice数组中间的操作
push和pop都是在数组末尾操作,相对比较简单,而shfit、unshfit、splice是在数组的开始或者中间进行操纵。我们来看一下,如果是这种情况的又是如何调整数组元素的。
(1)shift是出队,即删除并返回数组的第一个元素。shift和pop调的都是同样的删除函数,只不过shift传的删除的postion是AT_STRT,源码里面会判断如果是AT_START的话,会把元素进行移动:
if (remove_position == AT_START) {
Subclass::MoveElements(isolate, receiver, backing_store, 0, 1, new_length,
0, 0);
}
从1的位置移到0的位置,如上面第2行的第4、5个参数,这个move将会调leftTrim,和上面的rightTrim 相反:
*dst_elms.location() =
BackingStore::cast(heap->LeftTrimFixedArray(*dst_elms, src_index));
receiver->set_elements(*dst_elms);
(2)unshfit在数组的开始位置插入元素,首先要判断容量是否足够存放,如果不够,将容量扩展为老容量的1.5倍加16,然后把老元素移到新的内存空间偏移为unshift元素个数的位置,也就是说要腾出起始的空间放unshfit传进来的元素,如果空间足够了,则直接执行memmove移动内存空间,最后再把unshif传进来的参数copy到开始的位置:
int insertion_index = add_position == AT_START ? 0 : length;
// Copy the arguments to the start.
Subclass::CopyArguments(args, backing_store, add_size, 1, insertion_index);
// Set the length.
receiver->set_length(Smi::FromInt(new_length));
并更新array的length。
(3)splice的操作已经几乎不用去看源码了,通过shift和unshift的操作是怎么样的,就可以想象到它的执行过程是怎样的,只是shift/unshfit操作的index是0,而splice可以指定index。具体代码如下:
// Delete and move elements to make space for add_count new elements.
if (add_count < delete_count) {
Subclass::SpliceShrinkStep(isolate, receiver, backing_store, start,
delete_count, add_count, length, new_length);
} else if (add_count > delete_count) {
backing_store =
Subclass::SpliceGrowStep(isolate, receiver, backing_store, start,
delete_count, add_count, length, new_length);
}
// Copy over the arguments.
Subclass::CopyArguments(args, backing_store, add_count, 3, start);
它需要先shrink或者grow中间元素的空间,以适应增加元素比删除元素少或者多的情况,然后进行容量调整和移动元素。
接着再来看下两个“小清新”的函数
5. Join和Sort
说它们是小清新,是因为它们是用JS实现的,然后再用wasm打包成native code。不过,join的实现逻辑并不简单,因为array的元素本身具有多样化,可能为慢元素或者快元素,还可能带有循环引用,对于慢元素,需要先排下序:
var keys = GetSortedArrayKeys(array, %GetArrayKeys(array, length));
预处理完之后,最后创建一个字符串数组,用连接符连起来:
// Construct an array for the elements.
var elements = new InternalArray(length);
for (var i = 0; i < length; i++) {
elements[i] = ConvertToString(use_locale, array[i]);
}
if (separator === '') {
return %StringBuilderConcat(elements, length, '');
} else {
return %StringBuilderJoin(elements, length, separator);
}
而sort函数是用的快速排序:
function ArraySort(comparefn) {
CHECK_OBJECT_COERCIBLE(this, "Array.prototype.sort");
%Log("js/array.js execute ArraySort"); //手动添加的log打印,确保执行的是这里
var array = TO_OBJECT(this);
var length = TO_LENGTH(array.length);
return InnerArraySort(array, length, comparefn);
}
当数组元素的个数不超过10个时,是用的插入排序:
function InnerArraySort(array, length, comparefn) {
// In-place QuickSort algorithm.
// For short (length <= 10) arrays, insertion sort is used for efficiency.
function QuickSort(a, from, to) {
var third_index = 0;
while (true) {
// Insertion sort is faster for short arrays.
if (to - from <= 10) {
InsertionSort(a, from, to);
return;
}
//other code ...
}
}
}
快速排序算法里面有一个比较重要的地方是选择枢纽元素,最简单的是每次都是选取第一个元素,或者中间的元素,在源码里面是这样选择的:
if (to - from > 1000) {
third_index = GetThirdIndex(a, from, to);
} else {
third_index = from + ((to - from) >> 1);
}
如果元素个数在1000以内,则使用它们的中间元素,否则要算一下, 这个算法比较有趣:
function GetThirdIndex(a, from, to) {
var t_array = new InternalArray();
// Use both 'from' and 'to' to determine the pivot candidates.
var increment = 200 + ((to - from) & 15);
var j = 0;
from += 1;
to -= 1;
for (var i = from; i < to; i += increment) {
t_array[j] = [i, a[i]];
j++;
}
t_array.sort(function(a, b) {
return comparefn(a[1], b[1]);
});
var third_index = t_array[t_array.length >> 1][0];
return third_index;
}
先取一个递增间距200~215之间,再循环取出原元素里面落到这个间距的元素,放到一个新的数组里面(这个数组是C++里面的数组),然后排下序,取中间的元素。因为枢纽元素的刚好是所有元素的中位数时,排序的效果最好,而这里是取出少数元素的中位数,类似于抽样模拟,缺点是它得再借助另外的排序算法。
最后再比较一下Array和线性链接的速度。
6. Array和线性链接的速度
线性链接是一种非连续存储的数据结构,每个元素都有一个指针指向它的下一个元素,所以它删除元素的时候不需要移动其它元素,也不需要考虑扩容的事情,但是它的查找比较慢。我们实现一个简单的List和Array进行比较。
List的每个节点用一个Node 表示:
class Node{
constructor(value, next){
this.value = value;
this.next = next;
}
}
每个List都有一个头指针指向第一个元素,和一个length记录它的长度:
class List{
constructor(){
this.head = null;
this.tail = null;
this.length = 0;
}
}
然后实现它的push和unshift 函数:
class List{
unshift(value){
return this.insert(0, value);
}
push(value){
if(this.head === null){
this.head = new Node(value, this.tail);
this.length++;
} else {
this.insert(this.length, value);
}
return this.length;
}
}
两个函数都会调一个通用的insert 函数:
insert(index, value){
var insertPos = this.head;
//找到需要插入的位置的节点
for(var i = 0; i < index - 1; i++){
insertPos = insertPos.next;
}
var node = null;
if(index === 0){
node = new Node(value, this.head);
this.head = node;
} else {
node = new Node(value, insertPos.next);
insertPos.next = node;
}
this.length++;
return value;
}
有了这个List之后,就可以初始化一个list和array:
var list = new List();
var arr = [];
for(var i = 0; i < 100; i++){
list.push(i);
arr.push(i);
}
可以来比较这个List和Array的存储方式,非连续和连续的区别:
然后用下面的代码比较List和Array在数组起始位置插入元素的操作时间:
var count = 10000;
console.time("list unshfit");
for(var i = 0; i < count; i++){
list.unshift(i);
}
console.timeEnd("list unshfit");
console.time("array unshfit");
for(var i = 0; i < count; i++){
arr.unshift(i);
}
console.timeEnd("array unshfit");
再比较从正中间位置插入元素的时间:
console.time("list insert middle with index");
for(var i = 0; i < count; i++){
insertPos = list.insert(list.length >> 1, i);
}
console.timeEnd("list insert middle with index");
console.time("array insert middle");
for(var i = 0; i < count; i++){
arr.splice(arr.length >> 1, 0, i);
}
console.timeEnd("array insert middle");
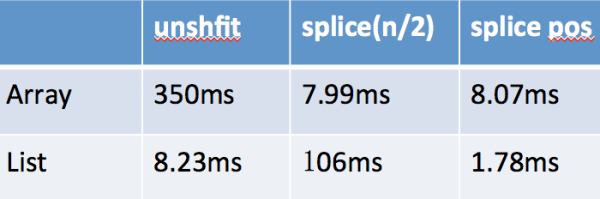
运行可以得到以下表格:
可以看到在队首插入元素,使用线性链接List的时间将会数量级的优于Array。如果是在中间位置插入的话,由于 List的查找花费了很多时间,导致总时间明显高于Array。但是如果在插入的时候,记住上一次的位置,那么List又会明显快于Array。如下换成记录插入的位置:
console.time("list insert middle with pos");
var insertPos = list.getNode(list.length >> 1);
for(var i = 0; i < count; i++){
insertPos = list.insertFromNode(insertPos, i);
}
console.timeEnd("list insert middle with pos");
时间比较List又快于Array:
综上,本文介绍了JS Array的实现,特别是它的操作函数,分析了它是怎么调整容量和移动元素的,并用了一个线性链接进行比较。Array的实现用了三种语言:汇编、C++和JS,最常用的如push用了汇编实现,比较常用的如pop/splice等用了C++,较为少用的如join/sort用了JS。
Array为快元素即普通的数组时,增删元素操作需要不断的扩容、减容和调整元素的位置。特别是当不断地在起始位置插入元素时,和链表相比,这种时间效率还是比较低下的。如果使用的场景是要根据index删除元素,使用Array还是有优势,但是若能够很快定位到删除元素的位置,链表毫无疑问是更合适的。
最后,他曾经分享过:
【第861期】从Chrome源码看浏览器如何计算CSS
【第901期】从Chrome源码看JS Object的实现
关于本文
作者:@李银城
原文:https://zhuanlan.zhihu.com/p/26388217
本篇文章为 @ 21CTO 创作并授权 21CTO 发布,未经许可,请勿转载。
内容授权事宜请您联系 webmaster@21cto.com或关注 21CTO 微信公众号。
该文观点仅代表作者本人,21CTO 平台仅提供信息存储空间服务。
评论
21CTO
管理团队最新文章
我要赞赏作者
请扫描二维码,使用微信支付哦。